


Deepmind, une filiale d’Alphabet, a encore frappé. Elle a mis au point une nouvelle IA, appelée AlphaZero. Cette fois, les algorithmes ont appris, seuls, sans intervention humaine et à partir de rien, à jouer au Go, aux échecs et au Shogi (également appelé échecs japonais). Trois jeux différents dont on lui a seulement fourni les règles.
Une nouvelle étape dans une courte histoire pleine de succès
En utilisant des réseaux neuronaux, AlphaZero a non seulement appris rapidement à maîtriser ces jeux mais est également devenue « le plus puissant joueur de l’histoire », s’enthousiasme Deepmind.
Cet engouement pour une de ses propres créations pourrait paraître un peu déplacé, mais Deepmind a un historique exceptionnel en la matière. Elle a sonné le glas de la domination de l’Homme sur la machine dans le domaine du Go.
En mai 2017, avant de prendre sa retraite après une brève carrière, AlphaGo, son intelligence artificielle, avait battu à plates coutures le meilleur joueur du monde dans un match en trois manches.
Après ce succès, Deepmind n’avait pas arrêté de travailler dans ce secteur. Elle a ainsi ensuite créé AlphaGo Zero, une intelligence artificielle qui a appris et maîtrisé le Go sans supervision humaine.
Trois intelligences artificielles de pointe balayées
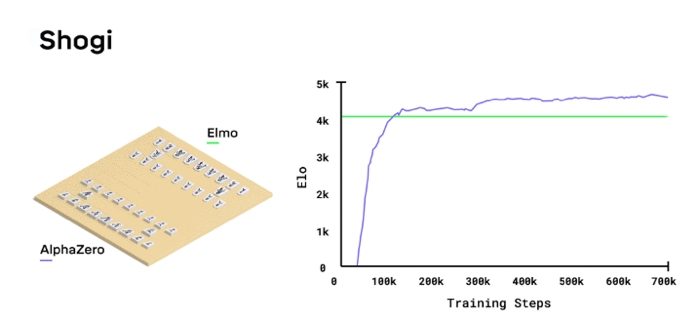
C’est sur ce savoir-faire que Deepmind a misé pour créer AlphaZero avant de la faire affronter AlphaGo Zero, Stockfish, une IA championne du monde d’échec et Elmo, une IA spécialisée dans le shogi.
Pour les défaire, il a fallu à AlphaZero des millions de parties pour y arriver. Elle a commencé par essayer des tactiques au hasard avant d’apprendre de ses erreurs et d’affiner ses stratégies, grâce à une technologie appelée apprentissage par renforcement.
Ces millions de parties auraient sans doute pris des années à des êtres humains, mais il n’a fallu à AlphaZero que neuf heures pour maîtriser les échecs, douze heures pour le shogi et treize jours pour faire de même avec le Go. Sachant qu’AlphaZero a commencé à battre des adversaires artificielles au bout de quatre heures pour Stockfish, deux heures pour Elmo et trente heures pour AlphaGo.
Ce sont pas moins de 5 000 TPU, tender processing unit, des processeurs conçus spécialement par Google pour le machine learning, qui ont été sollicités pendant cette phase d’apprentissage. Pour donner un aperçu de sa puissance, un TPU peut traiter pas moins de 100 millions d’images par jour sur les serveurs de Google Photos.
Des attaques et tactiques jamais vues
Ce débordement de puissance explique la rapidité de l’apprentissage et également le fait que AlphaZero, en utilisant une méthode appelée recherche arborescente Monte Carlo qui sert à prendre des décisions comme le prochain coup à jouer, a mis au point de nouvelles stratégies et de nouveaux coups, jamais vus, dans un jeu d’échecs.
Une réussite incroyable, c’est certain. Néanmoins, il ne faut une fois encore pas y voir la domination prochaine de l’Homme par la machine. Ces trois jeux, bien que complexes, ont pour point commun de se jouer à deux et toujours exposer toutes les informations requises.
Source :
Blog de Deepmind
👉🏻 Suivez l’actualité tech en temps réel : ajoutez 01net à vos sources sur Google, et abonnez-vous à notre canal WhatsApp.












