

Vous trouviez les expressions des Animojis ou des derniers Memojis d’Apple réussies ? Les dernières avancées de la recherche sur les deepfakes, notamment dans le domaine de la vidéo, risquent carrément de vous inquiéter. Ces vidéos – déjà interdites sur Twitter et Pornhub – plaquent les expressions d’un acteur anonyme sur le visage d’une célébrité. On peut même placer ce visage modifié d’une personnalité sur un autre corps et dans une tout autre situation que celle d’origine (d’où les craintes de la multiplication de fausses vidéos pornographiques).
La recherche dans le domaine avance à pas de géant pour des résultats de plus en plus réalistes. En témoigne cette vidéo mise en ligne le 17 mai dernier par un groupe de chercheurs issus des entreprises MPI Informatics et Technicolor ainsi que des universités de Munich, Bath et Stanford, fruit de leurs travaux qui seront présentés au SiGGRAPH au mois d’août prochain.
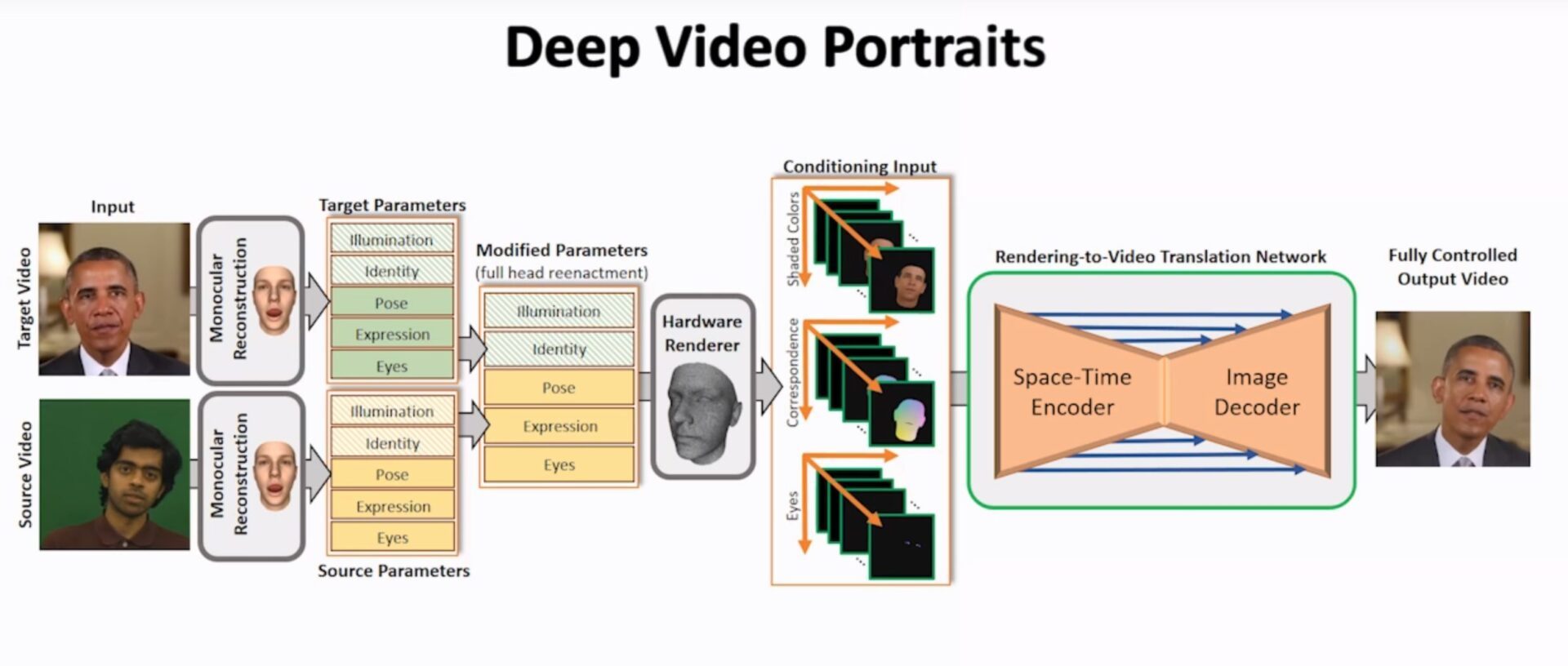
Dans cet extrait bluffant, on voit, par exemple, comment, en temps réel, il est possible d’appliquer les expressions et les mouvements de l’acteur au visage d’une autre personne. Tout cela grâce à un complexe système de superposition des expressions et un réencodage de l’ensemble grâce à de l’apprentissage machine.
Evidemment, le but des chercheurs n’est pas de faire avancer la science du deepfake ou promouvoir les fake news, ce qu’ils mentionnent clairement. Car cette technologie, baptisée Deep Video Portraits, pourrait avoir demain avoir mille autres usages, notamment dans le cinéma. Elle pourrait notamment servir à accélérer certains processus de post-production d’un film… Voire à révolutionner le doublage : Il suffirait que le doubleur prononce ce qu’il désire dans la langue cible pour que les mouvements faciaux de l’acteur en VO soient parfaitement restitués, par exemple.
Faire dire n’importe quoi à n’importe qui
Comment ça marche ? Trois facteurs sont pris en compte : les nuances de couleurs sur le visage, les mouvements de la tête et les yeux. Les actions de l’acteur source sont alors transposées sur une vidéo où la personnalité cible faisait tout autre chose. Même si elle ne parlait pas, on peut donc animer sa bouche pour que ses mouvements correspondent aux paroles qu’on veut lui faire prononcer.

On peut même mélanger deux vidéos d’une même personne pour lui faire dire la même chose, mais dans un autre contexte et un autre lieu. On imagine les dégâts de ce genre de vidéo dans l’exercice si délicat de la diplomatie internationale où les discours prononcés comptent autant que le lieu où on les tient.
Quand Barack Obama anime Vladimir Poutine
La source peut d’ailleurs aussi bien être un anonyme qu’une célébrité. Les chercheurs ont par exemple placé les expressions de Barack Obama sur le visage de Vladimir Poutine. Perturbant.

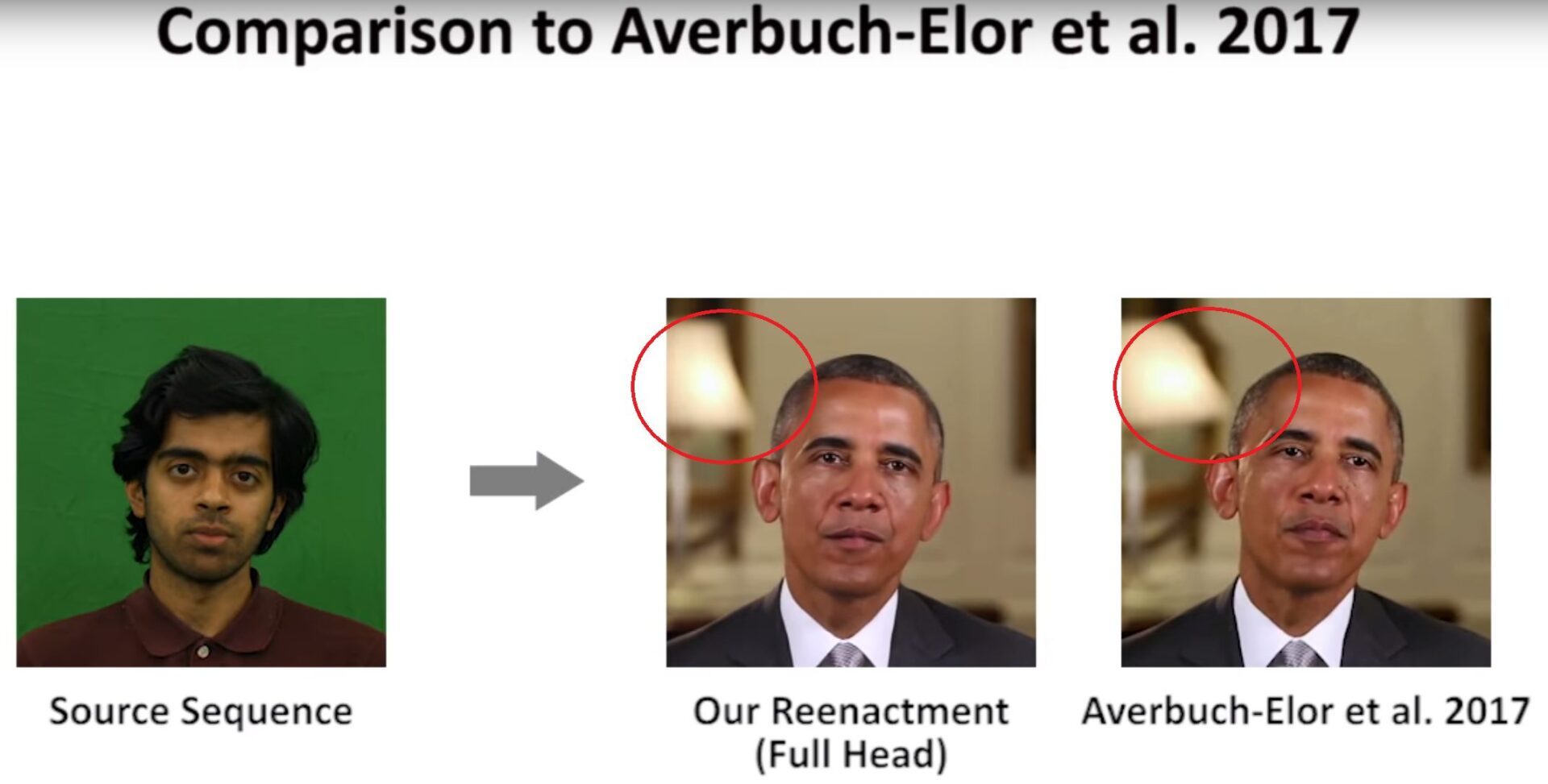
Et le réalisme augmente de jour en jour. L’ombre portée par la tête sur l’arrière-plan la suit désormais parfaitement. Par rapport à d’autres systèmes plus anciens comme Averbuch-Elor, on voit aussi que l’arrière-plan reste parfaitement immobile alors qu’il était auparavant déformé par les mouvements de tête qui n’existaient pas sur la vidéo d’origine.
Mais le plus impressionnant est la dernière partie de la vidéo où l’on voit que l’on peut tout simplement contrôler, comme on le souhaite, un visage en temps réel à l’aide d’une souris. Orientation de la tête, mouvement des lèvres, sourire, haussement de sourcil… ou quand Barack Obama et Theresa May deviennent de simples marionnettes !
👉🏻 Suivez l’actualité tech en temps réel : ajoutez 01net à vos sources sur Google, et abonnez-vous à notre canal WhatsApp.