De plus en plus faciles à réaliser, les deep fakes font l’objet de nombreuses recherches. À l’occasion de la conférence « Cybersec & AI 2020 », Hany Farid, professeur à l’université de Berkeley, a détaillé deux techniques intéressantes qu’il a co-développé récemment.
Pour les fausses stars…
La première est dédiée aux personnes importantes, telles que les chefs d’État, qui sont de plus en plus la cible de deep fakes ignobles pouvant faire boule de neige sur les réseaux sociaux. Pour détecter rapidement ces usurpations, l’idée est d’identifier une personne à protéger au travers de ses mouvements faciaux.
En effet, quand nous parlons, nous avons tous une façon particulière de bouger nos lèvres, de lever nos sourcils, de plisser les yeux, etc. Et tous ces petits mouvements se font, en plus, d’une manière coordonnée bien spécifique. Exemple : l’ex-président Barack Obama a parfois tendance à légèrement baisser la tête tout en abaissant les coins de sa bouche quand il annonce une mauvaise nouvelle. Une caractéristique qu’un deep fake n’imitera pas forcément.
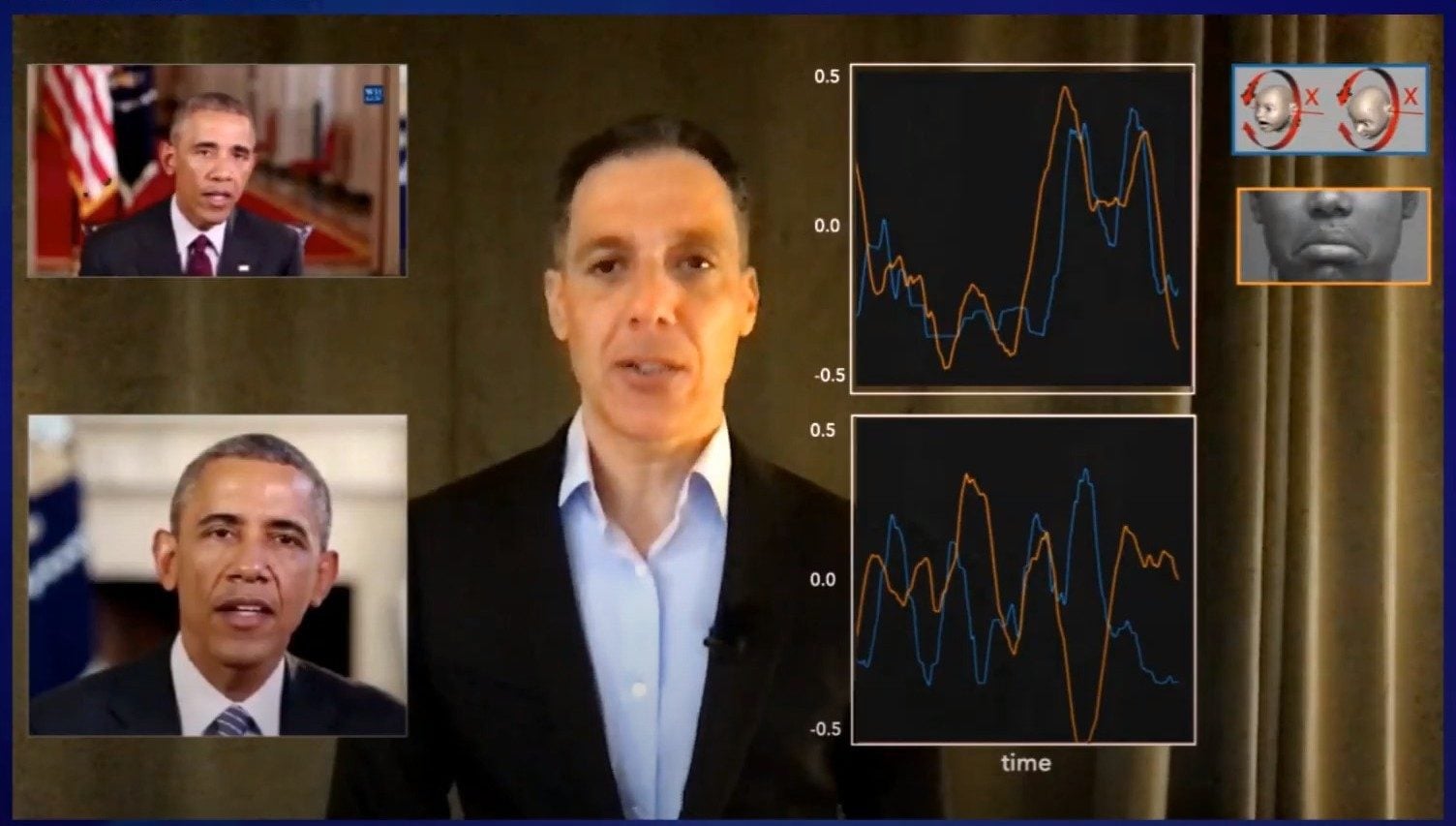
Ce type d’éléments peuvent être analysés et mesurés à partir de vidéos existantes pour créer une empreinte unique de 190 valeurs caractéristiques. Ce « vecteur d’empreinte » pourra être utilisé par la suite pour authentifier les vidéos.
Dans les tests effectués, le chercheur a obtenu un taux d’exactitude (« accuracy ») de plus de 93 %. Par ailleurs, cette technique serait plus robuste que celles fondées sur l’analyse de pixels.
Attention à la post-synchronisation
La seconde technique cible plus spécifiquement les deep fake de type « lip-sync », où la zone buccale est modifiée par un réseau neuronal pour coller avec un texte alternatif.
Hany Farid et ses confrères ont imaginé une technique qui analyse la cohérence entre les phonèmes et les visèmes, c’est-à-dire entre les sons et les expressions faciales élémentaires qui apparaissent lors de la parole.
Les chercheurs se sont surtout concentrés sur les phonèmes /m/, /b/ et /p/, car ils correspondent au même visème, celui d’une bouche fermée. Ce qui est visuellement plus facile à détecter et différencier.
Deux méthodes de détection automatisée ont été mises au point, l’une qui s’appuie sur une analyse de l’image, et l’autre sur un réseau neuronal. Dans les deux cas, on obtient des taux d’exactitude de plus de 90 %, ce qui est jugé prometteur.

Évidemment, ces techniques risquent d’être dépassées d’ici quelques années, car les créateurs de deep fake ne cessent de faire des progrès.
En théorie, ces derniers pourraient d’ailleurs les utiliser directement dans le cadre de réseaux neuronaux adverses génératifs (GAN, generative adversarial networks) pour optimiser leur travail de faussaire.
C’est pourquoi, d’ailleurs, Hany Farid et ses collègues ne publient jamais le code source de leurs détecteurs, mais seulement leurs papiers scientifiques. Pas question de donner un coup de main à l’ennemi.
👉🏻 Suivez l’actualité tech en temps réel : ajoutez 01net à vos sources sur Google, et abonnez-vous à notre canal WhatsApp.