« Le plus gros volume de données jamais analysé au monde ». C’est comme cela que David Doukhan, qui publie un rapport à propos du temps de parole des femmes dans les médias français, lundi 4 mars, introduit son travail pour l’Institut National de l’Audiovisuel (INA).
Sans surprise, elles parlent « deux fois moins que les hommes à la télévision et à la radio ». A l’écran, la voix des femmes représente seulement 32,7% du temps de parole total et derrière le micro, il descend à 31,2 %. Si le résultat n’est pas tellement nouveau, le volume de données analysées et l’outil d’analyse sont, eux, tout à fait inédits.
Un volume de données inédit
L’étude porte sur 22 chaînes de télévision et 21 stations de radio. Les données les plus anciennes remontent à 2001 pour la radio et 2010 pour la télévision et courent jusqu’à 2018. Enregistrés 24h/24 par l’INA, ces contenus audiovisuels sont aussi riches que gigantesques.
Or, un tel volume de données est difficilement analysable de manière non-automatisée. Et, la mesure manuelle du temps de parole est onéreuse. Donc, les études menées jusqu’ici sur le temps de parole (et non uniquement de présence) des femmes à l’antenne étaient limitées à des échantillons de la population. Ce qui par essence est biaisé, ne donnant pas une vision exhaustive de la situation analysée. L’inégalité genrée dans les médias, en l’occurrence.
Utiliser l’intelligence artificielle a permis d’automatiser le travail de recherche. Fruit d’une collaboration entre l’INA et le laboratoire d’informatique de l’université du Mans, le logiciel acoustique InaSpeechSegmenter permet de «localiser les zones de parole au sein de documents multimédias, et de déterminer le [genre] des locuteurs ». En utilisant des réseaux de neurones profonds (deep learning), l’algorithme est capable de distinguer une voix de femme ou d’homme, selon la fréquence du son émis.
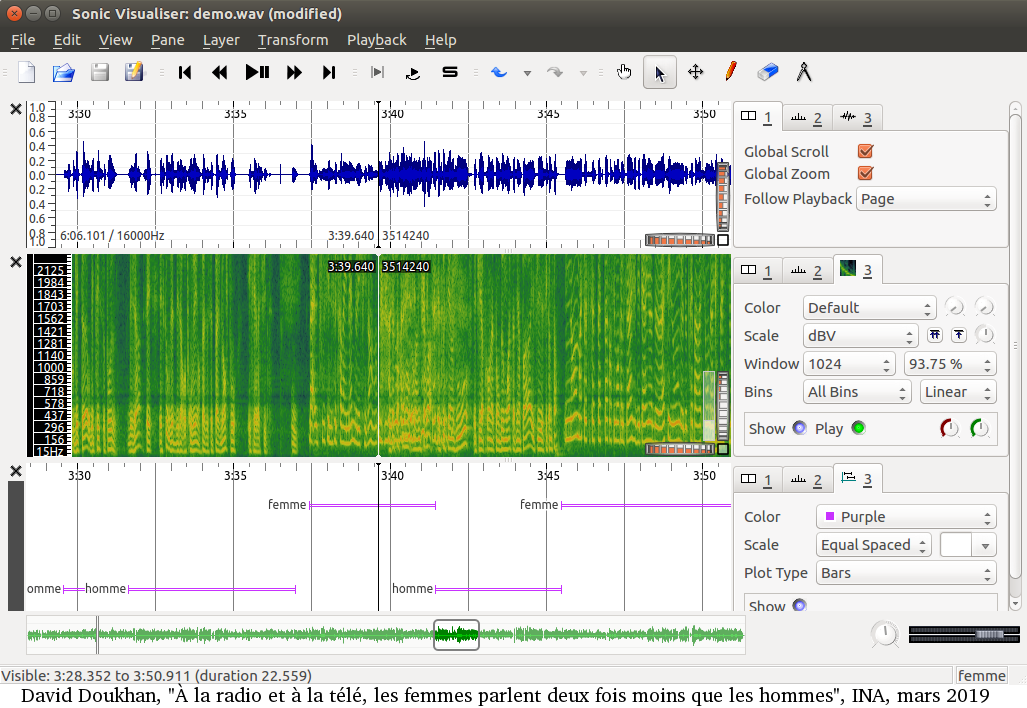
Pour bien comprendre, l’auteur décrit l’exemple d’analyse automatique reproduit ci-dessus dans une note universitaire explicative :
« La figure du haut représente le signal audio brut. La figure du milieu correspond à la représentation « temps-fréquence » du signal sonore, qui sert de base à son analyse automatique. La figure du bas représente les portions de signal qui ont été attribuées à des hommes (H) et à des femmes(F). »
Ce système a été entraîné à partir d’un dictionnaire gigantesque composé de 32 000 extraits sonores diffusés entre 1957 et 2012, dont 94 heures de voix d’hommes et 27 heures de voix de femmes enregistrées par l’INA. C’est la base d’apprentissage du logiciel.
Bientôt disponible sur data.gouv.fr
L’historique gigantesque sauvegardé par l’INA permet d’avoir un panorama fidèle à la réalité. David Doukhan revendique une marge d’erreur d’à peine 0,6% avec son programme d’analyse. Ce qui incite à se réjouir des conclusions encourageantes tirées par l’étude :
Le taux d’expression des femmes, toutes chaînes confondues, a évolué de 30,4 % en 2010 à 35,1 % en 2018. Cette évolution est particulièrement visible sur les chaînes publiques (+7 %). [Et à la radio, ndlr] le taux médian d’expression des femmes est passé de 25,1 % en 2001 à 34,4 % en 2018, soit une augmentation d’environ 0,5 % par an pendant 18 ans.
L’ensemble des indicateurs générés lors de cette étude devrait être mis à disposition sur data.gouv.fr, la plateforme ouverte des données publiques françaises. Ce qui assurera un suivi régulier d’un des pans majeurs de l’égalité entre les femmes et les hommes, décrétée comme « grande cause du quinquennat ».
👉🏻 Suivez l’actualité tech en temps réel : ajoutez 01net à vos sources sur Google, et abonnez-vous à notre canal WhatsApp.