

L’ère de la domination des puces graphiques (GPU) dans l’entraînement des intelligence artificielle (IA) ne touche peut-être pas à sa fin, mais les processeurs centraux des ordinateurs (CPU) pourraient revenir dans la course.
Détournés de leur tâche initiale dédiée aux rendus graphiques, notamment dans les jeux vidéo, les GPU sont utilisés depuis une décennie pour accélérer les calculs grâce à leurs hautes capacités de parallélisation. Éclipsant les CPU qui ont longtemps régné en maîtres dans les tâches de calculs, les GPU sont désormais rois dans de nombreuses tâches comme l’apprentissage profond des IA.
SLIDE, intelligence et optimisation pour tirer le meilleur du CPU
Mais la situation pourrait commencer à changer à la suite de la publication d’un article scientifique qui dévoile un algorithme de nouvelle génération. Appelé SLIDE pour « Sub-LInear DEep learning Engine », ou moteur d’apprentissage profond sous-linéaire, il s’agit d’un « moteur » de calcul qui mélange savamment algorithmes aux petits oignons, haute parallélisation (pour tirer parti de chaque cœur du CPU) et fines optimisations de charge.
Pour démontrer les capacités de leur nouveau moteur de calcul CPU, les chercheurs de l’université de Rice, dans le Texas, ont confronté le GPU champion de la catégorie « apprentissage profond », à savoir le NVIDIA Tesla V100 Volta (2017), à deux processeurs Xeon E5-2699A v4 fonctionnant à 2.40 GHz (lancés en 2016).
L’astuce tient dans deux éléments. D’une part, les CPU peuvent avoir accès à beaucoup plus de mémoire que les GPU. Sur ce point, les chercheurs soulignent dans leur article qu’il faut que cet accès mémoire soit bien géré pour ne pas rencontrer de problèmes qui ruineraient le fonctionnement de leur solution. Ils précisent par ailleurs que même sans optimisation et avec des problèmes, les résultats obtenus sont équivalents à ceux fournis par une plate-forme reposant sur des GPU… Cette plus grande quantité de RAM est donc bel et bien un avantage.
D’autre part, l’autre point fort de cette solution est le caractère « intelligent » du moteur logiciel. Pour l’entraînement de réseaux neuronaux, les GPU utilisent une grande quantité de données et sollicitent aveuglément tous les types de neurones pour n’importe quel type de calcul.
Plutôt que de mobiliser tous les neurones artificiels de manière non spécifique et brutale, le moteur SLIDE n’entraînent que les bons neurones pour la bonne tâche.
Un changement total d’approche
C’est là que réside une partie essentielle du génie de ce projet. Pour pouvoir déterminer quels neurones sont pertinents, les chercheurs ont totalement changé l’approche de l’entraînement des réseaux neuronaux.
Comment ? En abandonnant un point fondamental, mais parfois décrié de l’entraînement des réseaux neuronaux, la back propagation (ou rétropropagation du gradient, en français). Autrement dit, pour faire simple, la méthode par laquelle les neurones font évoluer le « poids » accordés aux résultats pour obtenir la bonne réponse.
L’« approche fondamentalement différente » des chercheurs de l’université de Rice consiste à entraîner les réseaux neuronaux comme s’il s’agissait d’un contexte de recherche, reposant sur des tables de hachage. Cette approche a pour conséquence première de réduire considérablement les besoins en calcul… et donc de gagner beaucoup de temps.
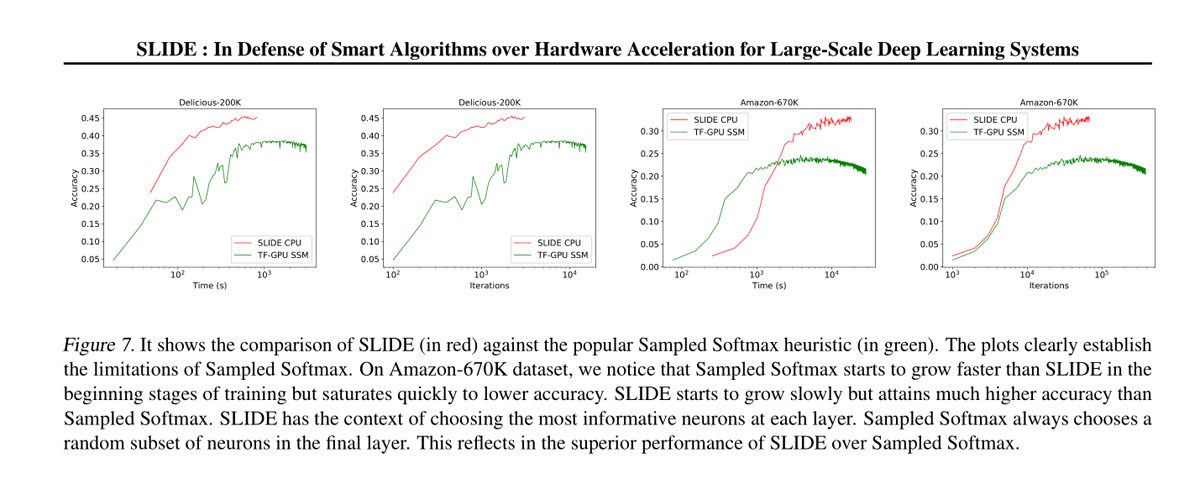
Quel bilan pour cette expérience ?
Grâce à cette méthode, les deux Xeon se sont montrés jusqu’à 3,5 fois plus performants que le gros NVIDIA Tesla V100 Volta dans le traitement de sets de données connus des chercheurs tel qu’Amazon-670K. Autrement dit, un même entraînement qui a pris 3h30 avec TensorFlow, un des meilleurs outils d’apprentissage du marché, et une plate-forme à base de Tesla V100, n’a pris qu’une heure, sans GPU, et avec une plate-forme CPU de classe Xeon à 44 coeurs.
S’il est plus facile de rajouter des GPU que des CPU dans un système pour accélérer les performances, les chercheurs soulignent « qu’il y a encore beaucoup de moyens d’optimiser (le système). Nous n’avons pas encore utilisé les unités vectorielles, ou les accélérateurs intégrés aux CPU tel que le Deep Learning Boost d’Intel. »
En clair, la marge de progression semble importante. S’ajoute à cela un avantage de coût : quand la paire de Xeon s’affiche à 5300 € (HT), une seule Tesla V100 coûte le double. Elle doit en plus être intégrée dans un système qui intègre de toute façon des processeurs professionnels de type Xeon.
Vu les besoins de puissance et la faciliter d’ajouter des cartes GPU pour améliorer les performances des serveurs et autres fermes de calcul, les processeurs graphiques ont encore de beaux jours devant eux.
Mais les CPU reviennent clairement dans la course et pourraient prendre l’avantage notamment dans des systèmes où le coût ou l’espace occupé est limité, comme le Spaceborne Computer envoyé par HPE dans la station spatiale internationale.
D’autant que Anshumali Shrivastava, l’inventeur principal à la tête du projet dévoile un dernier avantage de sa solution :
« SLIDE gère les données en parallèle. […] J’entends par là que si j’ai deux instances de données, par exemple, l’une est une image de chat et l’autre une image d’un bus, elles activeront différents neurones. SLIDE pourra alors mettre à jour ou entraîner ces deux neurones indépendamment.»
Voilà peut-être bien l’utilisation optimisée du parallélisme que le CPU attendait pour revenir dans la course…
Sources : Arxiv.org et Rice University via Engadget
👉🏻 Suivez l’actualité tech en temps réel : ajoutez 01net à vos sources sur Google, et abonnez-vous à notre canal WhatsApp.












