


L’intelligence artificielle connaît un vent de démocratisation sans précédent, grâce à l’arrivée d’agents conversationnels comme ChatGPT. Ils permettent de montrer l’un des pans les plus spectaculaires des capacités de l’apprentissage profond et de l’intelligence artificielle au grand public : par une démonstration à s’approprier le langage des humains et discuter avec eux sans être à côté de la plaque.
Vous vous êtes certainement déjà demandé comment, en aussi peu de temps, nous étions passés d’une relation avec la machine essentiellement par du code à ce langage naturel si simple, qui ne demande qu’à se laisser imaginer parler avec un autre être humain. C’est ici que le modèle de langage entre en jeu. Tout en restant un modèle informatique utilisant des vecteurs et des fonctions, il fait office de tampon entre deux entités que tout semblait séparer : l’humain et la machine.
Introduction au modèle de langage
Les modèles de langage sont donc des systèmes informatiques avec comme mission de traduire le langage naturel à la machine, et permettre à celle-ci de comprendre, analyser et répondre à des demandes, de traduction, de résumer, mais aussi de simuler l’imagination, la réflexion, et prendre en compte ce qui avant ne pouvait pas se schématiser et se théoriser sous la forme de fonctions : les nuances culturelles, les sentiments et les émotions.
Depuis 2017, une révolution émerge avec la montée en puissance des LLM (large language models) tels que les Transformers de Google, qui poussent à un niveau inégalé la pertinence de compréhension et de réponse textuelles au langage naturel. Désormais, les modèles mathématiques réalisés par les machines se confondent avec la vraie intelligence humaine, avalent des quantités astronomiques de données et établissent leurs capacités de réponse sur des milliards de paramètres.
Les mots ne sont plus analysés ni générés l’un après l’autre : la machine arrive à prendre un propos dans son ensemble en un rien de temps, et proposer des analyses, des résumés, des traductions ou encore des corrections et des essais bien plus vite que n’importe quel humain.
Glossaire
Pour pouvoir entrer dans la définition du modèle de langage et in fine pouvoir expliquer comment fonctionne un agent conversationnel, nous allons devoir utiliser des expressions et un vocabulaire spécifique. Avant de commencer, tentons de réaliser un petit glossaire.
Agent conversationnel : plus communément appelé « chatbot », il s’agit d’une application permettant d’envoyer des requêtes textuelles et d’en obtenir des réponses. ChatGPT et Google Bard sont des agents conversationnels basés sur l’IA et un modèle de langage. Précédemment, les agents conversationnels pouvaient se trouver de forme plus limitée comme avec les assistants numériques.
Données séquentielles : toutes les phrases, les paragraphes, les documents sont des exemples de données séquentielles. Dans le traitement du langage naturel, l’ordre des mots dans une phrase ou d’autres unités textuelles est essentiel pour comprendre le sens global.
Entrées et sorties : les entrées sont généralement les données séquentielles envoyées par l’internaute. Les sorties sont les données séquentielles générées par la machine en prenant en compte les entrées et d’autres paramètres tels que les précédentes données séquentielles, les données du modèle linguistique obtenues grâce à son entraînement, etc.
Paramètres : pour pouvoir comprendre, analyser et proposer des réponses à une entrée, les modèles linguistiques utilisent tout un ensemble de paramètres, qui s’obtiennent par l’entraînement d’une IA. On appelle ces paramètres des poids, qui sont ajustés par rapport aux exemples de la base de données. Plus il y a de paramètres, plus le modèle linguistique est censé pouvoir mieux analyser les entrées et proposer des sorties plus complexes.
NLP (Natural Language Processing) : tous les domaines de compétence de la discipline de traitement du langage naturel. Il peut s’agir de la traduction, du résumé, de la génération ou encore de la classification de texte. Des outils comme ChatGPT regroupent tous ces éléments.

Définition d’un modèle de langage pour IA
Le modèle de langage qui se cache derrière un agent conversationnel de type ChatGPT ou Bard est un système qui permet à une machine de comprendre et générer du texte au langage naturel, celui de l’humain. Pour pouvoir parler dans une langue, comprendre le contexte, ressentir le ton et toute autre subtilité, l’aspect culturel, apprendre des schémas et proposer des réponses pertinentes, le modèle de langage doit s’appuyer sur une grosse quantité de données et savoir comment la traiter et correctement l’appliquer avec les entrées de l’utilisateur.
Certains modèles de langage limités fonctionnent sur un modèle statistique pur quand d’autres, comme les LLM, fonctionnent avec de l’apprentissage automatique. Les modèles de langage les plus aboutis sont à la fois capables d’analyser la relation entre tous les mots et groupes de mots, le contexte, et garder en mémoire les séquences textuelles précédentes pour prendre en compte un contexte de temporalité. Il s’appuie sur bien plus de paramètres et font entrer d’autres techniques comme les « tokens » et les « masks ».
Les modèles de langage sont le coeur informatique des agents conversationnels : ils entrent en jeu au moment où l’entrée textuelle de l’internaute est convertie en suite de chiffres, que l’on appelle des vecteurs, pour être analysés via de multiples types d’encodeurs, de décodeurs, suivant des méthodes qui ont évolué, du modèle n-grams au LLM, en passant par les réseaux récurrents. Son rôle prend fin au moment de la sortie textuelle générée par la machine, puis affichée sur l’écran de l’internaute.
Le rôle des vecteurs
Dans tous les cas, ces modèles sont des modèles mathématiques qui prédisent la probabilité qu’un mot ou qu’une séquence de mots apparaisse dans la phrase. Les modèles passent donc par un vrai traitement informatique – ce n’est pas de la magie. Ils traduisent par des modèles algorithmiques, ce qui implique donc que le système transforme les entrées en nombres avant de les transformer ensuite à nouveau en texte pour les sorties.
Entre-temps, ils deviennent des suites de nombres que l’on appelle des vecteurs. Dans les NLP, ces vecteurs permettent notamment de donner une classification relative aux autres mots, et ainsi établir des scores de proximité entre eux. Le nombre de chiffres d’un vecteur détermine le nombre de dimensions du modèle. Ces vecteurs sont déterminants pour définir le sens de chaque mot, rendre mathématique le langage naturel et permettre à la fin de mimer la compréhension humaine et son langage.
Au fil du temps, les vecteurs ont aussi commencé à être utilisés pour prendre en compte des points plus subtils du langage naturel : comme les sous-entendus, les émotions, l’humour.
Le rôle de l’intelligence artificielle
Le modèle de langage est un élément central dans l’univers de l’intelligence artificielle du traitement du langage naturel (NLP). Quel est alors le rôle de l’intelligence artificielle ? Pour pouvoir constituer un modèle linguistique de qualité, il faut prendre en considération une quantité colossale de données, ne serait-ce que pour établir une classification des mots entre eux, leurs similarités, leurs différences, etc. Pour cela, les réseaux de neurones permettent de faire le travail titanesque que ferait un humain, sans effort et en un temps record.
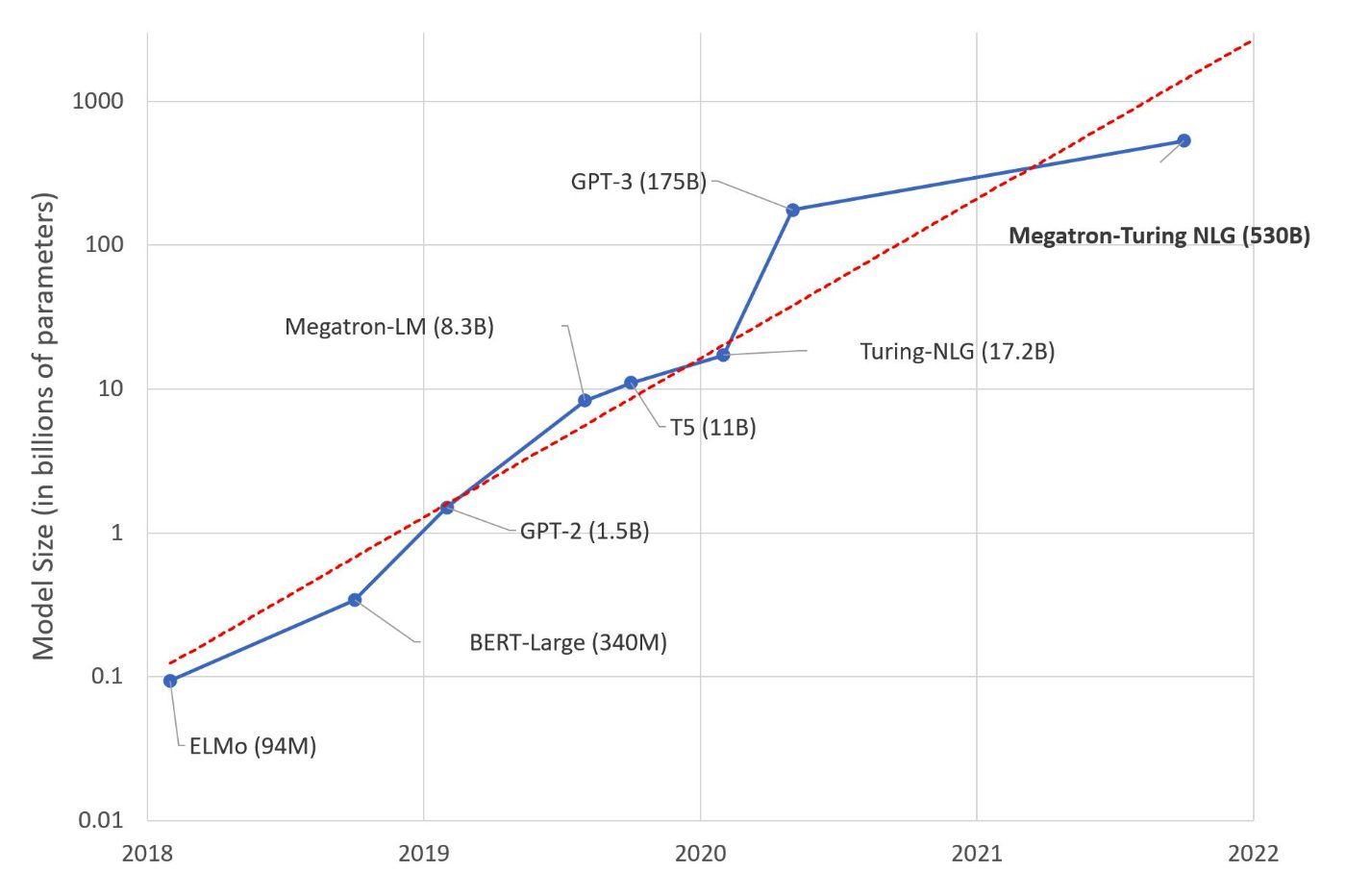
La place de l’IA dans les modèles de langage se trouve donc notamment dans l’entraînement à partir de très grande quantité de données textuelles – généralement les LLM sont pré-entraînés sur un ensemble de plus de 10 000 milliards de mots (10B) en provenance notamment de Common Crawl, The Pile, MassiveText, Wikipedia et GitHub. Mais l’intelligence artificielle est aussi présente ensuite, pour aider la capacité du modèle à proposer des réponses contextuelles et intelligentes, et en continuant son apprentissage notamment.
Aujourd’hui, les capacités des modèles de langage ont progressé avec l’arrivée du machine learning et même du deep learning. Les modèles de langage atteignent 70 B de paramètres sur Llama 2 de Meta et 175 milliards sur le GPT-3 de OpenAI. Les principaux connus du grand public (et utilisés) sont des large language models (LLM), mais pour en arriver à ce que l’on connaît aujourd’hui, ces modèles se sont appuyés sur d’autres plus limités, mais qui ont chacun mis leur pierre dans la conception des LLM.
Le rôle d’un réseau récurrent
Avant d’arriver au modèle des LLM qu’on connaît aujourd’hui, les modèles linguistiques se sont d’abord appuyés sur le concept de réseaux récurrents. Ces modèles traitent les données textuelles de façon numéraire et analysent chaque vecteur de chaque mot avec un vecteur de pensée. Le vecteur de pensée suit le même principe et il est donc peaufiné après l’ajout de chaque nouveau mot dans une phrase. À l’image d’un cerveau humain qui, durant une lecture, découvre le sens d’une phrase mot après mot et permet de se faire une pensée d’une phrase grâce à chaque mot lu à la suite, le réseau récurrent peut donc avoir une bonne compréhension et offrir des sorties plus pertinentes et dans le contexte grâce à ce vecteur.
Le rôle des Transformers
Les larges language models (LLM) ne sont pas arrivés du jour au lendemain. Entre eux et les réseaux récurrents se sont présentées plusieurs versions améliorées, qui tentaient de corriger les défauts dans la compréhension des modèles, notamment à cause de la limite de mémoire et la pondération de l’importance des mots. On peut notamment citer les Long Short-Term Memory (LSTM) et les Gated Recurrent Unit (GRU). Mais la vraie révolution des modèles de langage remonte à 2017 et la présentation du modèle de Transformers par des chercheurs de Google, qui a conduit à l’émergence du principe le plus populaire des LLM.
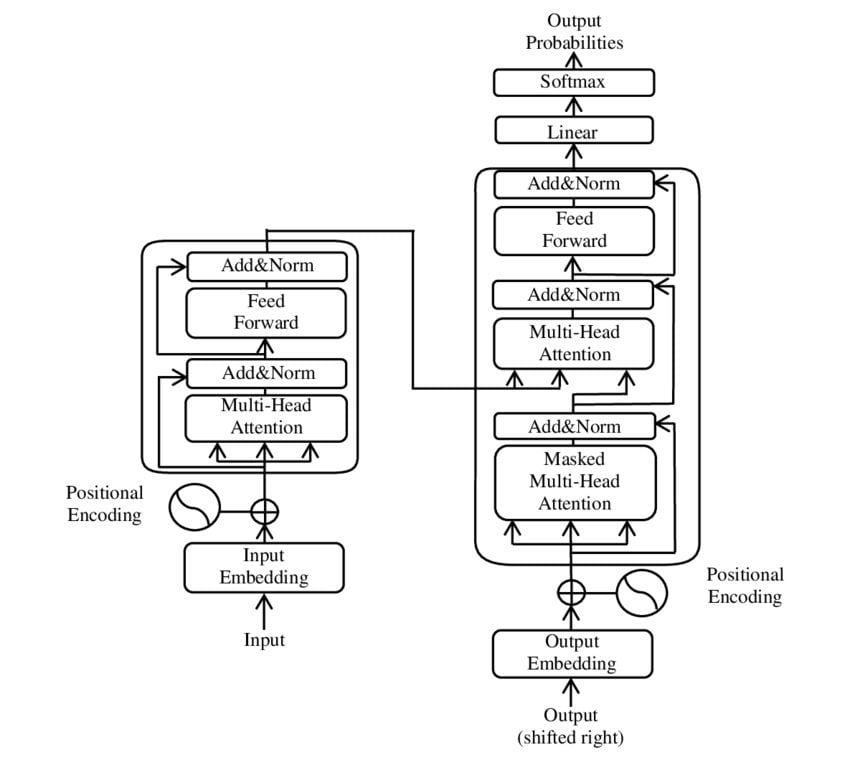
Les Transformers sont différents des réseaux récurrents dans leur approche : au lieu d’analyser chaque mot, il analyse toute une phrase ou un ensemble de phrase. La pondération de chaque vecteur lié à un mot passe alors par un principe de token et de masks. Les transformateurs sont une architecture qui permet une nouvelle façon de modéliser les données contextuelles et les données textuelles. De quoi abolir au problème de mémoire, de place des mots dans la phrase, d’établir des relations non locales des mots.
Les « masks » se caractérisent sous deux genres : les filtres de causalité, pour influencer un vecteur plutôt qu’un autre en fonction du contexte de la phrase, et les filtres de padding, qui n’ont aucune influence sur la compréhension ou les réponses, mais permettent seulement de normaliser les phrases de longueur différentes en des phrases de même taille (on reste sur des mathématiques, tout doit être carré) en y ajoutant des mots… qui ne servent à rien et qui ne doivent pas être pris en compte par la machine.
Les tokens quant à eux, viennent enrichir les vecteurs des réseaux récurrents en ajoutant bien plus de choses en considération et une dimension bidirectionnelle dans la compréhension de chaque mot. Il y a par exemple le token de caractéristiques (appelé « embeddings »), qui sont ajoutés à des couches d’attention qui pondère l’importance de chaque mot dans une phrase et vient établir un lien entre chaque mot sans que cela ne vienne complexifier le sens global. Les différents modèles de langage continuent d’optimiser ces tokens et le traitement de ces derniers.
Google, qui avait tout d’abord dévoilé BERT, a depuis lancé LaMDA (aussi écrit Lambda) et enfin PaLM (pour la compréhension généralisée du langage et l’intégration de plusieurs sources d’information). OpenAI se base aussi sur un modèle de transformers avec GPT-3, GPT-3.5 et GPT-4. La première version de son modèle de langage date de 2018. Aujourd’hui GPT-4 se distingue par un nombre d’entrées plus important (il n’est pas limité à des entrées textuelles et accepte aussi les images ou l’audio) et les paramètres seraient bien plus importants que les 175 milliards de poids de GPT-3.
Les limites du modèle de langage
Il faut distinguer deux choses : les limites des modèles de langage et les limites du modèle de langage en général. Remettre en question un type de modèle de langage est différent de remettre en question la capacité d’évolution du modèle de langage dans son ensemble.
Or, existerait-il des solutions pour agir totalement différemment dans ce qui est de l’interaction avec la machine par le langage naturel ? À ce jour, tous les modèles de langage ont leurs limites, mais toute piste d’amélioration passe encore par le même principe global du modèle linguistique et l’enrichissement algorithmique… loin de quelconque comparaison avec l’âme et la conscience humaine.
Le principe du modèle linguistique reste ainsi particulièrement dépendant d’un entraînement de qualité avec un accès à une data importante, mais pas indéfinie (faute d’avoir les ressources informatiques nécessaires). En parallèle, les modèles de langage ne savent rien, à proprement parler. Ils ne se contentent que de faire des analogies et ne mémorisent pas. D’où la prépondérance de réponses inventées, plus communément comparées à des « hallucinations ».
Au final, se pencher sur les modèles linguistiques pour comprendre les agents conversationnels est similaire à ouvrir les portes d’un data-center pour comprendre le fonctionnement (et les limites) d’Internet. La magie que procure aujourd’hui ChatGPT s’explique et le fruit de son travail revient bien à des systèmes finis, imaginés et mis en place par l’Humain.
Chez Meta, le développement de l’intelligence artificielle est une histoire en partie française. Après plusieurs années à travailler avec Jérome Pesenti, le chercheur et lauréat du prix du Prix Touring Yann LeCun a abordé en juin dernier le sujet d’un nouveau modèle linguistique du nom de JEPA (« Joint Embedding Predictive Architecture »), avec comme avancée majeure d’avoir « des machines au moins aussi intelligentes que les humains, si ce n’est plus », expliquait celui à la tête de la recherche scientifique de l’IA au sein de la maison-mère de Facebook. Avec JEPA, l’architecture du modèle de langage prendrait en compte de nouveaux facteurs pour « comprendre le monde sous-jacent ».
« Aujourd’hui, le machine learning est vraiment pourri par rapport à ce que les humains peuvent faire. […] Par conséquent, quelque chose d’énorme nous échappe », ajoutait Yann LeCun, qui ne mâchait pas ses mots et déclarait aussi que « l’IA d’aujourd’hui et l’apprentissage automatique sont vraiment nuls. Les humains ont du bon sens alors que les machines, non ». Pour lui, la piste sur laquelle se pencher est avant tout l’aspect cognitif, le fonctionnement même du cerveau humain. Les modèles de langage s’attardant trop sur la simple théorisation du langage et du poids des mots.
Conclusion : quand le tour de magie nous dépassera vraiment
Grâce aux modèles de langage, l’intelligence artificielle a appris comment parler. Du modèle n-grams aux larges language models (LLM), il est au centre des agents conversationnels et il est au final la véritable surprise que les internautes ont pu découvrir avec la sortie en fin d’année dernière de ChatGPT. Si Google, Meta, OpenAI et tant d’autres peaufinent leur propre technologie, tous comptent aujourd’hui sur la logique de système de modèle de langage pour pouvoir connecter l’humain à la machine dans une presque parfaite illusion de dialogue entre deux individus.
Dans les discussions, on préfère pourtant rattacher l’effet waouh à l’intelligence artificielle au sens large, sans citer et expliquer le fonctionnement, parfaitement connu par ses créateurs, du système de retranscription du langage naturel en suites de chiffres, de vecteurs de « tokens », de « masks », d’entrées et de sorties qui n’ont pas grand-chose à voir avec l’apprentissage cognitif. Mais trêve de critiques, le modèle de langage est et reste pour le moment le seul à offrir aux agents conversationnels et aux autres outils du domaine du NLP les moyens de ses ambitions.
Logique cognitive et ordinateur quantique
On mime ainsi la déduction, l’analyse, la réflexion… mais les résultats proposés par les agents conversationnels, bien qu’ils bluffent, laissent un peu à la vue de tous le secret de leur tour de magie. À l’avenir, le modèle de langage devra donc continuer à gagner en dimensions et en capacité de fonctionnement. Dans un avenir de plus en plus proche, c’est à travers le hardware que les pistes d’amélioration seront les plus grandes : l’arrivée de l’ordinateur quantique permettra aux modèles de langage et à l’IA d’aller au-delà des échelles actuelles.
Tous les modèles à ce jour ne se valent pas et certains retournent à la base de la logique quand on fait face à une limite : se focaliser sur un seul but et laisser de côté l’intelligence artificielle globale – l’agent conversationnel qui a réponse à tout. Beaucoup d’entreprises trouveront plus intéressant d’ailleurs de se spécifier à un domaine, notamment dans la recherche (comme la recherche médicale et biologique) et la communauté qui se partage les idées et avance ensemble sur des modèles open source se donne déjà rendez-vous sur une plateforme bien connue dans le milieu de l’IA : Hugging Face.
Là où nous devrons nous pencher, c’est sur les limites du modèle de langage au sens large. Remettre en question son existence revient à remettre en question le coeur même du fonctionnement des NLP à ce jour. À partir de là, de nouveaux systèmes pourraient naître et englober un système plus large, qui cherchera cette fois-ci à simuler et mimer le cognitif propre à l’humain. De là, le tour de magie sera plus grand – l’illusion ne sera plus le lapin dans le chapeau, mais le magicien lui-même.
En resterons-nous toujours à de la magie, d’ailleurs ?
👉🏻 Suivez l’actualité tech en temps réel : ajoutez 01net à vos sources sur Google, et abonnez-vous à notre canal WhatsApp.











Chouette article,merci
🙌🏽