


Comme prévu, NVIDIA, l’une des entreprises qui bénéficie le plus de l’essor de l’IA, a profité de la GTC (GPU Technology Conference), qui se déroule cette semaine à San Jose en Californie, pour présenter ses nouveaux GPU ; pas encore les GeForce RTX 50 Series, mais plutôt les GPU Blackwell destinés aux centres de données et pour lesquels la firme a déjà anticipé une très forte demande. Jensen Huang, son PDG, a ainsi dévoilé les successeurs des H100, H200 et GH200 : les B100 et B200, qui s’inscrivent dans la lignée des deux premiers, ainsi que le GB200, hériter du dernier.
Blackwell, ou le passage au MCM
C’était pressenti depuis plusieurs mois, et c’est désormais officiel : l’architecture Blackwell marque l’adoption de la conception MCM (Multi-Chip Module). Déjà utilisée par AMD, elle permet davantage de flexibilité que l’ancien design monolithique. Blackwell bénéficie du processus 4NP (4 nm) de TSMC.

La star est bien sûr le B200. Il répond à la nécessité, formulée par Jensen Huang, « d’avoir de plus gros GPU » pour répondre aux besoins de l’IA générative. Sur scène, l’homme à la veste en cuir a comparé directement une puce Hopper à un GPU Blackwell ; et effectivement, il y a une différence de taille. À la décharge de Hopper, le B200 n’est toutefois pas un GPU unique au sens traditionnel du terme. Il est constitué de deux puces qui fonctionnent comme une GPU CUDA unifié. Elles sont connectées par une connexion NV-HBI (NVIDIA High Bandwidth Interface) de 10 To/s.

Sans tomber dans une énumération de valeurs, le B200 comporte 208 milliards de transistors, contre 80 milliards pour les H100 / H200. Armée de 192 Go de mémoire HBM3e offrant une bande passante de 8 To/s, la puce délivre des performances d’IA cinq fois supérieures à son modèle. Plus précisément, Blackwell fournit, par puce, 2,5 fois les performances de son prédécesseur en FP8 pour l’entraînement et 5 fois en FP4 pour l’inférence. Notez cependant que la précision FP4 est spécifique à la nouvelle architecture Blackwell (qui ajoute également un nouveau format FP6). En conséquence, il faut plutôt se baser sur le FP8 pour comparer Blackwell et Hopper. De plus, la consommation augmente, avec environ 1000 W par puce, contre 700 W pour les GPU Hopper.

Par ailleurs, l’interconnexion NVLink de cinquième génération, deux fois plus rapide que Hopper, prend en charge jusqu’à 576 GPU.
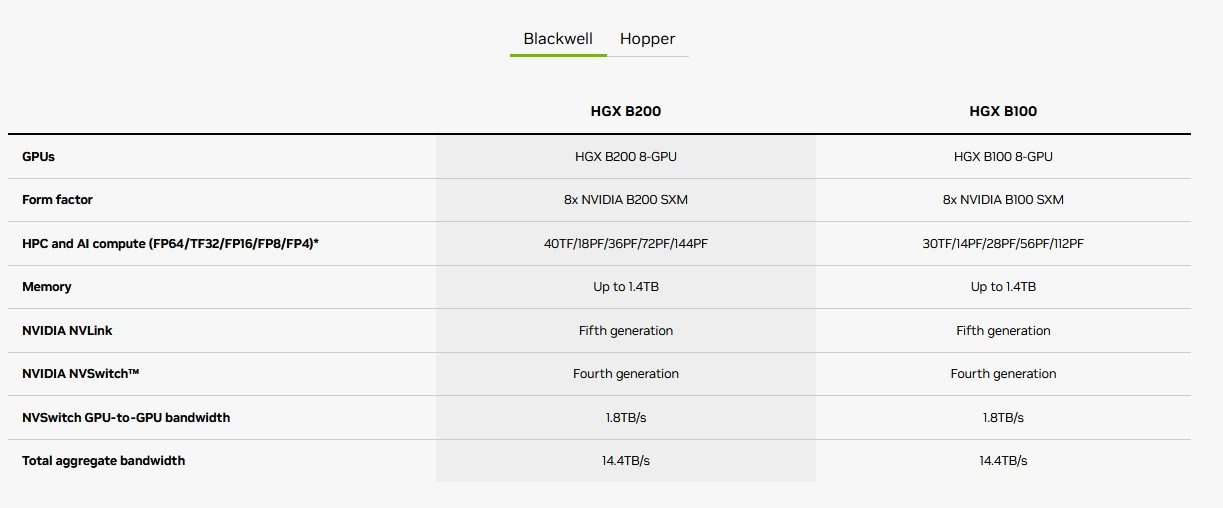
Le B100 n’a pas eu droit à une exposition aussi complète. Comme son numéro l’indique, il s’annonce un peu moins puissant que son modèle. NVIDIA le mentionne simplement pour certains produits, comme les HGX B100 mentionnés ci-dessous. Notre confrère d’AnandTech suggère qu’il s’agit d’un unique die à 104 milliards de transistors, mais cette assertion nécessitera confirmation.
Un B200 décliné à toutes les sauces
Pour en revenir au B200, il va également servir au GB200 Grace Blackwell. C’est le descendant de la GH200 Grace Hopper Superchip. Nous retrouvons une paire de B200 associée à un CPU NVIDIA Grace (72 cœurs Arm Neoverse V2). L’ensemble possède jusqu’à 384 Go de HBM3e. Le TDP est de 2700 W.

Pour être complets, évoquons aussi les stations DGX B200 qui embarquent huit GPU B200 et deux processeurs Intel Xeon Platinum 8570 ; et, pour parler du B100, les HGX B200 et HGX B100 dotés de 8 GPU B200 / B100 au format SXM (Server PCI Express Module).
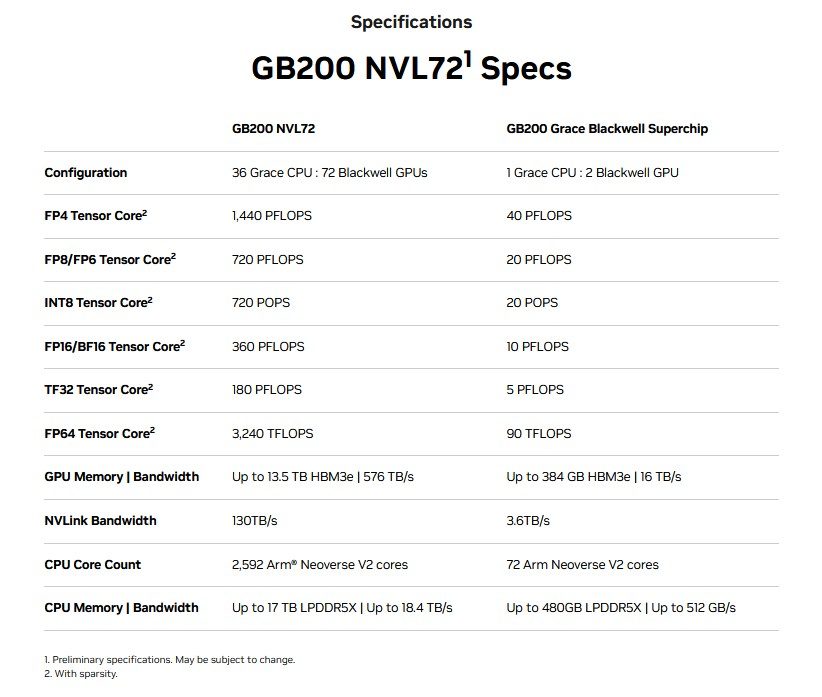
Enfin, couplées à d’autres puces appelées NVLink Switch chargées de gérer les interconnexions NVLink, les GB200 sont les briques du GB200 NVL72, un système multi-nœuds, refroidi par liquide, à l’échelle du rack. Au menu : 36 CPU Grace et 72 GPU Blackwell, pour 720 pétaflops de performances d’entraînement IA et 1,4 exaflops de performances d’inférence IA.

Au sujet du GB200 NVL72, Jensen Huang a déclaré : « Il n’y a que quelques machines exaflopiques, peut-être trois, sur la planète à l’heure où nous parlons. Il s’agit ici d’un système d’IA exaflopique dans un seul rack ».
Terminons par une petite note culture. Le nom de l’architecture de NVIDIA est un hommage à David Harold Blackwell, mathématicien de l’Université de Californie à Berkeley spécialisé dans la théorie des jeux et les statistiques, et premier chercheur noir à avoir été intronisé à la National Academy of Sciences.
👉🏻 Suivez l’actualité tech en temps réel : ajoutez 01net à vos sources sur Google, et abonnez-vous à notre canal WhatsApp.
Source : NVIDIA












