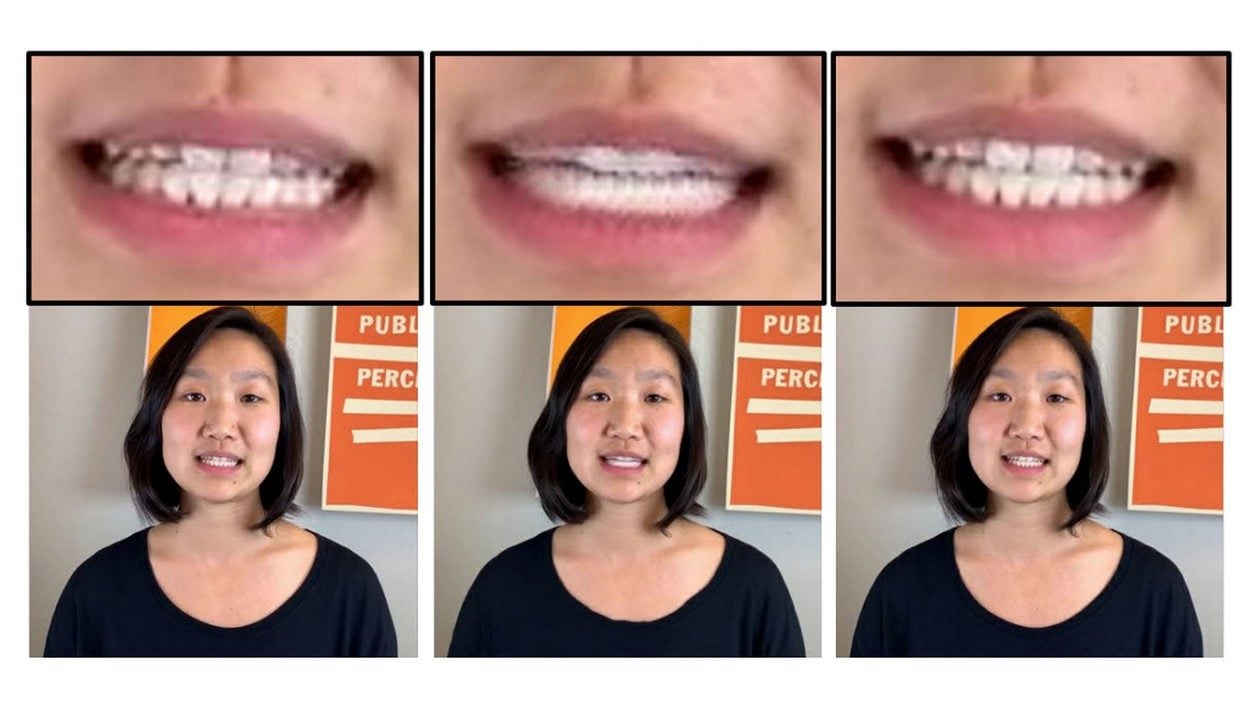
Modifier de manière automatique une interview vidéo n’a jamais été aussi simple. Des chercheurs des universités de Princeton et Stanford, ainsi que de l’institut Max Planck, viennent de publier une technique qui permet de modifier le contenu d’une allocution vidéo simplement en modifiant le texte de la retranscription verbale. Le système est alors capable, à partir du nouveau texte, de créer l’entretien vidéo correspondant, sans coupures ni à-coups, comme si elle était d’origine. On peut ainsi ajouter et supprimer des mots, ou se contenter de les réarranger. Le résultat est tellement bluffant que la plupart des personnes qui visionnent ces vidéos modifiées pensent qu’elles sont véridiques. Des exemples sont montrés dans une vidéo de présentation sur YouTube.
D’autres chercheurs explorent également ce domaine de la génération automatique de vidéos. En 2017, un groupe de l’université de Washington avait notamment réussi à créer une vidéo artificielle de Barack Obama à partir d’une piste audio existante. Comparativement, la technique que viennent de présenter les chercheurs de Princeton et de Stanford est supérieure, car elle évite d’avoir à réaliser un enregistrement audio : il suffit de modifier un texte.
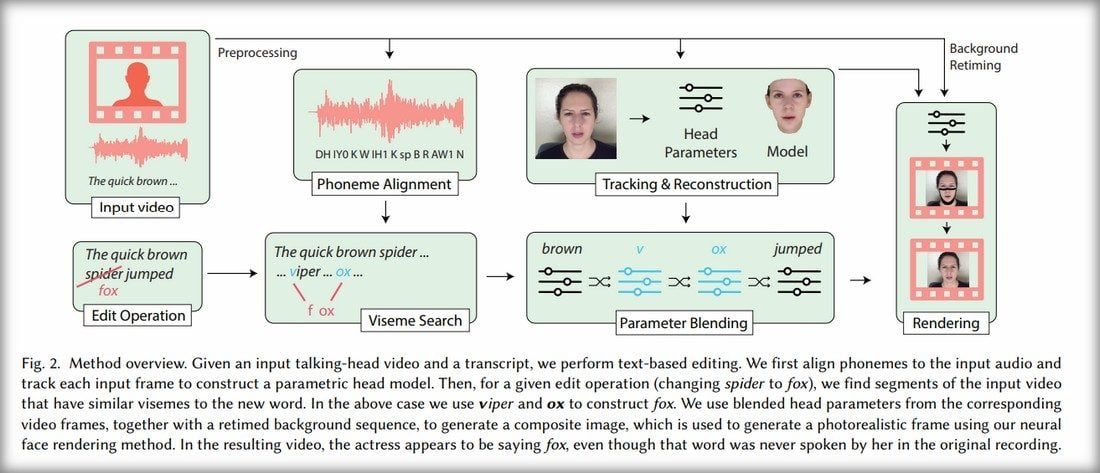
Comment ce travail de modification est-il réalisé ? Le système créé par les chercheurs va d’abord analyser la vidéo et la retranscription verbale pour reconnaître non seulement les phonèmes, mais aussi les « visèmes ». C’est-à-dire les expressions faciales élémentaires associées aux phonèmes. Le système va ensuite analyser les modifications apportées au texte et identifier les visèmes qu’il faut utiliser pour modifier la vidéo.
Une modélisation 3D, puis un réseau de neurones
Les nouvelles séquences sont alors créées en deux étapes. Dans un premier temps, le logiciel va générer une modélisation 3D des mouvements de la bouche et de la mâchoire, tout en respectant les conditions générales de la vidéo : exposition, éclairage, position de la tête, etc. Dans un second temps, un réseau de neurones préalablement entraîné va transformer ces modélisations 3D en séquences vidéos réalistes. Pour la partie audio, les chercheurs utilisent différentes méthodes : soit ils réenregistrent le nouveau texte avec la personne d’origine, soit ils génèrent artificiellement les nouvelles parties audio avec un logiciel tel qu’Adobe VoCo.
Evidemment, les chercheurs ne souhaitent pas que leur technologie soit utilisée pour manipuler de façon malveillante des discours ou des interviews. Ils le voient comme un outil supplémentaire dans les processus de production audio-vidéo, par exemple pour corriger des erreurs d’enregistrement. Le logiciel pourrait également servir à générer des séquences vidéos réalistes pour un assistant virtuel.
Dans tous les cas, l’utilisation de cette technologie devrait se faire de manière ouverte et transparente, et avec l’accord de la personne filmée. Pour éviter les créations frauduleuses et malveillantes, les chercheurs estiment qu’il faudrait développer davantage de techniques de vérification, comme l’analyse forensique ou le watermarking.
Source: Site web du projet
👉🏻 Suivez l’actualité tech en temps réel : ajoutez 01net à vos sources sur Google, et abonnez-vous à notre canal WhatsApp.