


Pour beaucoup de personnes, Google n’est qu’un aspirateur à données personnelles. Mais, là aussi, les temps changent. La firme de Mountain View se positionne de plus en plus souvent comme défenseur de la vie privée. En août dernier, elle a présenté « Privacy Sandbox », un concept technologique qui fait le grand écart entre ciblage publicitaire et protection des données personnelles.
Google vient maintenant de publier en open source une librairie C++ d’algorithmes de confidentialité différentielle (CD) ou « differential privacy ». Disponible sur GitHub, elle est censée offrir une boîte à outils prête à l’emploi pour tous ceux qui manipulent d’importantes masses de données et qui souhaitent préserver l’anonymat des données sous-jacentes. « Ce n’est pas la première librairie de ce type, mais c’est probablement la plus complète et la plus rodée », nous explique Miguel Guevara, responsable produit au sein de l’équipe Privacy de Google.
Simple sur le principe, mais complexe à implémenter
Cette librairie, en effet, est utilisée par Google sur le plan opérationnel dans certains de ses produits, par exemple dans Google Maps pour créer les indicateurs d’affluence des commerces ou de popularité des plats dans les restaurants. En 2014, Google avait par ailleurs utilisé des technologies de CD pour collecter des données télémétriques dans Chrome.
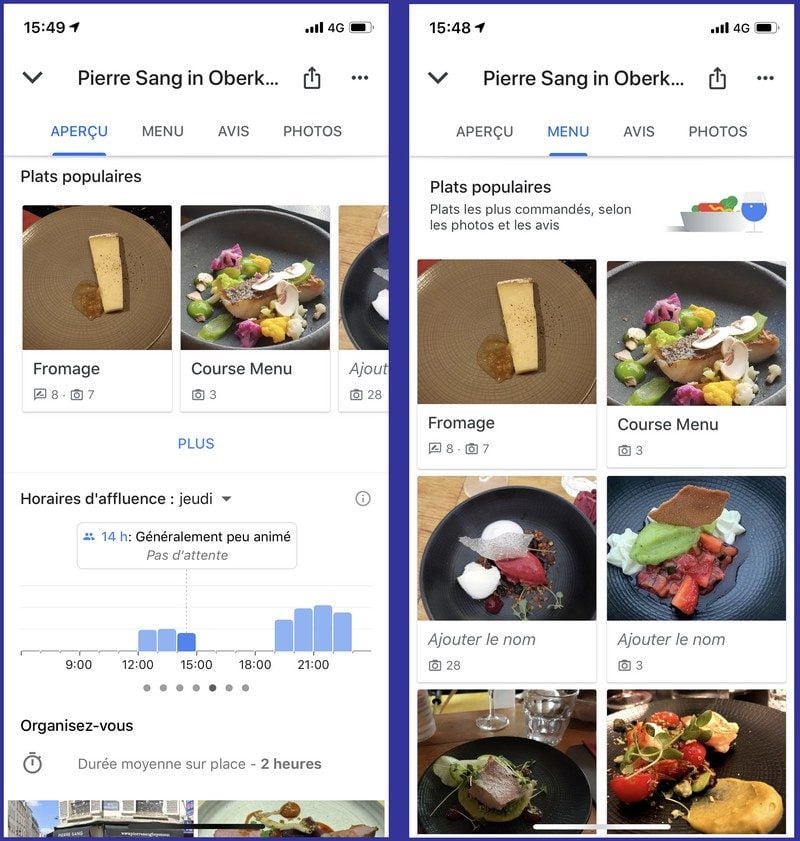
Sur le principe, la CD est assez simple à comprendre. Pour anonymiser des données, il ne suffit pas de supprimer les noms des personnes, car des recoupements de données pourraient quand même permettre de retrouver l’identité. Avec la CD, l’idée est d’injecter dans les données un signal aléatoire qui brouille suffisamment les pistes pour empêcher les recoupements d’informations, sans pour autant dénaturer la validité statistique des traitements.
« Les méthodes de CD sont très solides. Elles peuvent même être prouvées de manière formelle et leurs effets sont mesurables. Mais elles sont quand même difficiles à implémenter, surtout si les bases de données sont complexes. Cette librairie facilite ce travail d’implémentation et nous espérons qu’elle sera largement utilisée », nous précise Damien Desfontaines, chercheur au sein de l’équipe Privacy et doctorant à l’ETH de Zurich. D’autres outils de protection de données ont également été publiés cette année à destination des développeurs, comme « Tensorflow Privacy », « Tensorflow Federated » et « Private Join and Compute ».
Source: Google
🔴 Pour ne manquer aucune actualité de 01net, suivez-nous sur Google Actualités et WhatsApp.












