


A chaque fois qu’une nouvelle technologie révolutionnaire est apparue, des questions d’ordre éthique et juridique se sont rapidement posées : Quelles sont ses limites d’usage ? Comment s’assurer qu’elle ne provoque pas de conséquences néfastes pour les utilisateurs ? Qui est responsable si quelque chose dérape ?
L’intelligence artificielle n’échappe pas à cette règle. La question de l’éthique est même particulièrement importante étant donné l’impact de cette technologie -et en particulier sa variante de l’apprentissage automatique-, sur des aspects de notre vie quotidienne toujours plus nombreux. Les algorithmes d’intelligence artificielle décident ce que nous voyons sur Internet, évaluent notre solvabilité, copilotent nos avions et nos voitures, nous proposent des produits à acheter, aident les médecins à détecter nos maladies et à nous prescrire des médicaments, peuvent reconnaître notre voix et notre visage à la maison ou ailleurs, etc.
L’épineux problème de la voiture autonome
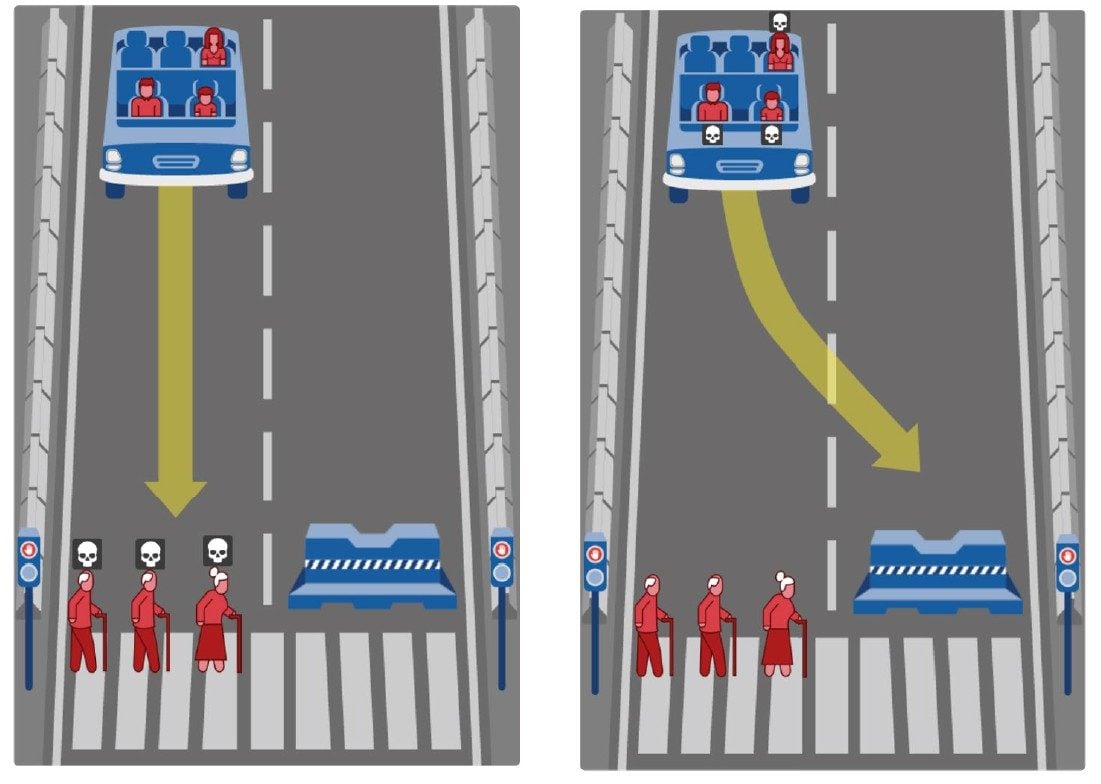
Mais créer un cadre éthique pour un programme n’est pas si facile. Il ne suffit pas d’implémenter les trois lois de la robotique qu’avait imaginées Isaac Asimov en 1942. Celles-ci se prêtent bien à la narration, mais elles sont beaucoup trop simplistes, comme le montre l’exemple de la voiture autonome. Comme on ne pourra jamais éliminer le risque d’un accident, il faut prévoir à l’avance les décisions épineuses qu’un pilote automatique doit prendre en fonction des nombreux cas divers et variés. Si un accident est inévitable, mais qu’il est possible d’ajuster la trajectoire finale, que faut-il privilégier ? Faut-il sauver la vie des deux personnes âgées qui traversent la route, quitte à rentrer dans un mur et tuer les jeunes passagers ? Faut-il préserver davantage la vie des femmes que celle des hommes ? Celle des enfants plutôt que celle des personnes âgées ? Celle des riches au détriment de celle des pauvres ?
Un sondage mondial effectué en 2018, et baptisé « The Moral Machine Experiment », montre que tous les peuples n’ont pas la même façon de voir les choses. Dans les sociétés individualistes, comme les pays d’Amérique du nord, on préfère sauver un maximum de gens, indépendamment des caractéristiques personnelles des victimes. Dans les sociétés collectivistes, comme certains pays asiatiques, on préfère préserver la vie des personnes âgées par rapport à celle des jeunes. Et dans les pays latins, comme la France, on a tendance à vouloir préserver davantage la vie des femmes que celles des hommes. Bref, non seulement les règles sont parfois complexes à formuler, mais en plus il n’est pas toujours possible de les rendre universelles. Ce qui n’a pas empêché l’Allemagne à formuler, dès 2017, un premier guide éthique pour l’élaboration de voitures autonomes et connectées.
Toutefois, même si l’on a des idées claires et nettes sur le cadre éthique qu’il faut respecter, on n’est jamais à l’abri d’un biais, c’est-à-dire d’une erreur systématique mais involontaire par rapport aux règles posées. Les exemples en la matière sont nombreux. En 2015, la reconnaissance d’images de Google confond des citoyens afro-américains avec des gorilles. En 2016, un chatbot de Microsoft commence tout d’un coup à parler comme un néo-nazi. La même année, le site ProPublica révèle qu’un logiciel d’évaluation du risque de récidive, baptisé Compas, avait la main lourde sur les cas des Américains noirs qui, du coup, écopaient de peines plus lourdes que les Américains blancs.
Ces biais sont difficiles à prévoir. Dans le cas de Compas, les développeurs avaient supprimé de leurs données d’analyse celles qui étaient relatives à l’origine ethnique ou géographique, afin d’éviter ce type de discrimination. Et pourtant, le logiciel a généré un important biais ethnique. « En raison des corrélations qui peuvent exister entre les données, il est possible qu’un programme d’apprentissage automatique réintroduise un biais qu’on a voulu éliminer à la base. Le cas de Compas montre que supprimer des données n’est pas suffisant », explique Rachel Orti, experte technique au Software Lab d’IBM France, à l’occasion de la conférence AI Paris 2019. De multiples organisations se sont depuis créées pour insuffler de l’éthique dans les algorithmes d’apprentissage automatique. Parmi elles: AI For Good Foundation, Data For Good, Fair By Design, Algorithmic Justice League, Algorithm Watch, The Institute for Ethical AI & Machine Learning, etc.
Il faut mettre en place un processus éthique
Mais alors, comment faire pour éviter qu’une intelligence artificielle dérape et fasse le mal au lieu de faire le bien ? Le respect de l’équité et de la non-discrimination n’est malheureusement pas une science exacte. « Il n’existe pas de librairie logicielle permettant d’implémenter de l’équité dans un logiciel. C’est quelque chose qui doit se résoudre par l’application de bonnes pratiques et la mise en place d’un processus qu’il faut documenter avec précision », explique Joaquin Quinonera Candela, directeur au sein de l’entité Facebook AI, à l’occasion d’une conférence de presse à Paris.
Un bon point de départ est de consulter les sept principes éthiques édictés en avril 2019 par la Commission européenne et de s’imprégner des contraintes légales fixées par le règlement européen RGPD, entrée en application depuis mai 2018. L’article 22, en particulier, précise qu’un « traitement automatisé » ne peut pas, en général, prendre de décision fondée sur des données personnelles, comme l’origine raciale, les opinions politiques, les convictions religieuses, etc.
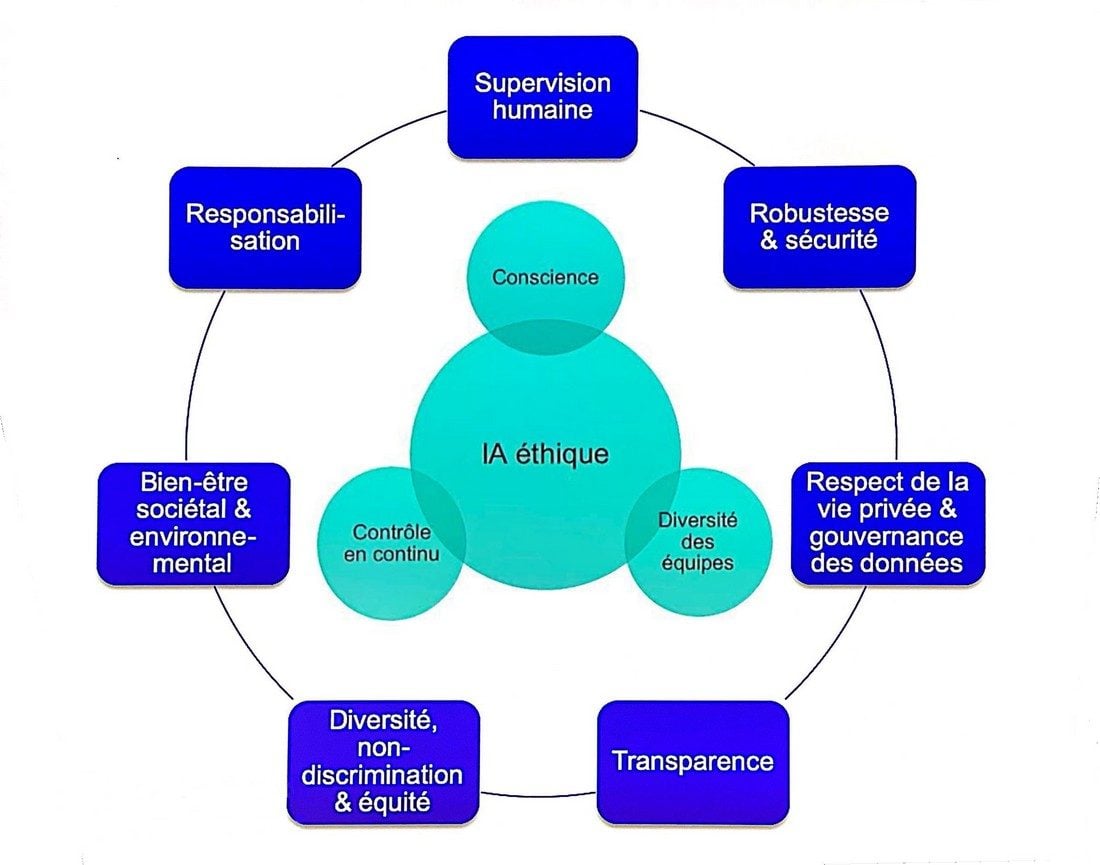
La lutte contre les biais passe ensuite par l’implication de personnes diverses dans le projet de développement, tant au niveau du genre que de l’origine ethnique, sociale, intellectuelle, professionnelle, etc. « Plus il y aura de personnes diverses, plus il y aura de questions différentes relatives à l’impact du logiciel d’intelligence artificielle sur la vie des gens. Ainsi, on sera capable de prendre en compte beaucoup plus de cas de figures, et cela dès la phase de conception », souligne Mélanie Rao, développeuse au Software Lab d’IBM France.
Les biais peuvent se nicher dans différentes parties d’un système d’apprentissage automatique. Les données utilisées pour entraîner l’algorithme peuvent créer un biais si certains groupes sont surreprésentés ou sous-représentés. Un défaut peut également être généré au moment de l’étiquetage des données. Celui-ci se fait à la main et s’appuie sur un jugement humain, donc potentiellement faillible et biaisé. Un cas typique est la détection de fausses informations sur Facebook. « C’est complexe, car la définition d’une fausse information peut varier d’une personne à l’autre. Il est donc nécessaire de disposer d’une grande variété de superviseurs », explique Joaquin Quinonera Candela.
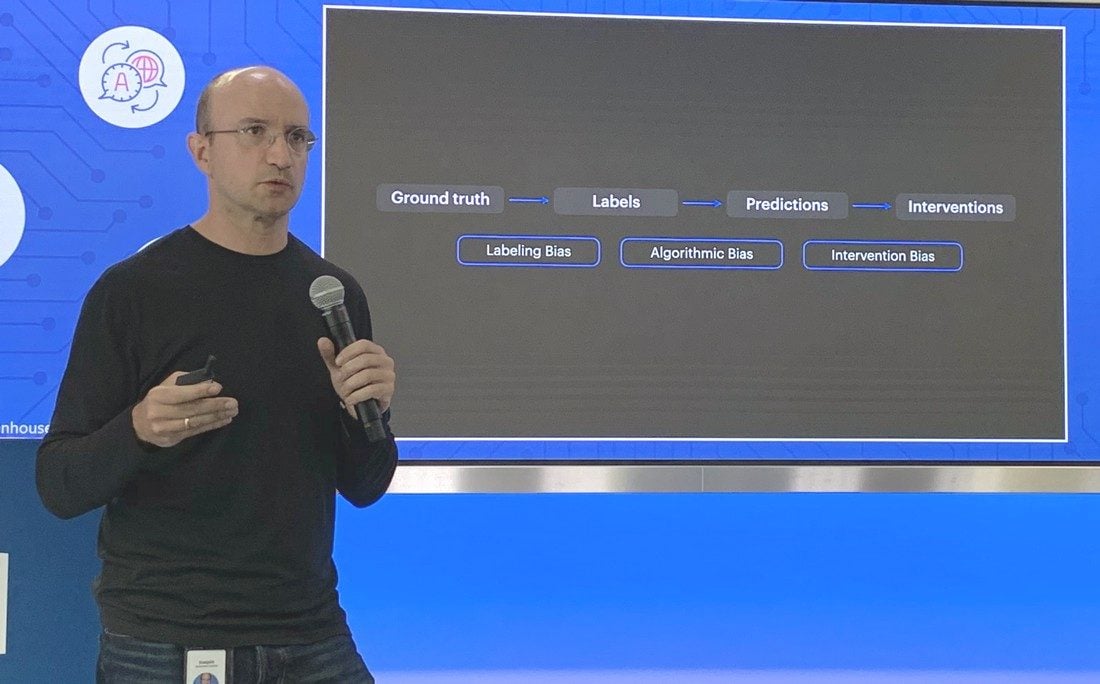
Les biais peuvent également se nicher dans la manière dont l’algorithme va traiter les données étiquetées et parvenir à une évaluation (exemple : la probabilité qu’il s’agisse d’une fausse information). Ainsi que dans la manière dont cette évaluation va générer une décision (exemple : c’est bien une fausse information). « Au final, les prédictions doivent être bien calibrées et il faut éviter les divergences entre les différents groupes d’utilisateurs », souligne le directeur de Facebook AI.
Des outils et des métriques
La bonne nouvelle, c’est que les développeurs commencent à disposer d’une palette d’outils open source qui leur permet de détecter ces biais. Ces outils s’appuient sur des « métriques » probabilistes qui, si elles dévient de la normale, vont générer des alertes et des pistes pour résoudre le problème. IBM fournit un logiciel baptisé « AI Fairness 360 » avec plus 70 métriques. La société Pymetrics a créé « Audit AI », une librairie Python pour tester une dizaine de métriques. Et Google propose son « What-if Tool » qui permet de jouer avec 5 métriques et un « variateur de seuil ». De son côté, Facebook a développé un outil interne baptisé « Fairness Flow », qui n’est pas librement disponible.
Mais même avec ces outils, on n’est pas à l’abri d’une mauvaise surprise. « Toute la difficulté, c’est de choisir les bonnes métriques pour une intelligence artificielle donnée. Cela se fait au cas par cas », explique Mélanie Rao. Evidemment, si l’on ne choisit pas les bonnes métriques, on risque de ne pas découvrir certains biais cachés.
Bref, on le voit, la création d’un logiciel d’intelligence artificielle éthique et responsable est loin d’être facile. C’est un parcours semé d’embûches et de chausse-trappes. Pour y arriver, il faut non seulement une grande technicité, mais aussi veiller au respect d’un processus ouvert qui permette de contrôler et surveiller chaque étape de l’élaboration. Complexe.
🔴 Pour ne manquer aucune actualité de 01net, suivez-nous sur Google Actualités et WhatsApp.







