


DeepMind vient de réaliser un grand coup en matière d’intelligence artificielle. La filiale britannique d’Alphabet a dévoilé cette semaine AlphaGo Zero, une évolution encore plus puissante et efficace du fameux programme AlphaGo, qui avait pourtant déjà terrassé le joueur professionnel Lee Sedol en 2016 et le champion du monde Ke Jie cette année.
AlphaGo Zero a atteint le niveau d’un grand maître en trois jours
A la différence des précédentes IA de DeepMind, qui s’étaient nourries de millions de parties de Go pour mieux appréhender le jeu, AlphaGo Zero n’a pas eu besoin d’ingérer des données humaines pour progresser. Ses concepteurs lui ont simplement inculqué les règles du jeu.
Après des premières parties forcément hasardeuses, il a découvert rapidement les meilleurs stratégies pour gagner en s’exerçant contre lui-même, devenant en quelque sorte son propre professeur. Il ne lui a fallu que trois jours (mais 4,9 millions de parties tout de même) pour écraser 100 à 0 la machine AlphaGo Lee… qui avait elle-même démoli Lee Sedol. Et 40 jours d’entraînement pour surpasser AlphaGo Master, qui détenait le titre de meilleur joueur mondial. A titre de comparaison, il aurait fallu 33 siècles à un être humain pour espérer parvenir à ce résultat en accumulant le même nombre de parties !
Les méthodes utilisées
- Faire jouer la machine contre elle-même, cela s’appelle de l’apprentissage par renforcement. La plupart du temps, cette méthode est couplée à celle de l’apprentissage supervisé qui consiste à produire des règles à partir d’une base de données contenant des exemples. La particularité d’AlphaGo Zero, c’est de ne pas avoir eu recours à l’apprentissage supervisé. «Jusqu’à maintenant, AlphaGo reposait essentiellement sur de l’apprentissage profond de type supervisé et, dans une moindre mesure, sur du renforcement. La nouvelle version n’utilise plus que du renforcement », nous résume Tristan Cazenave, professeur à l’Université Paris Dauphine et expert en intelligence artificielle.
- Il ne s’agit pas d’une première. DeepMind avait ainsi déjà réussi en 2015 à faire apprendre à jouer à des jeux Atari à une intelligence artificielle, sans aucune base de données d’apprentissage à l’entrée. « Ce n’est pas le premier logiciel qui apprend par lui-même, la nouveauté c’est que AlphaGo Zero soit si bon », a commenté le futurologue Anders Sandberg, de l’Université d’Oxford pour l’AFP.
- Autre différence, AlphaGo Zero ne repose plus que sur un seul réseau neuronal quand les précédentes versions en nécessitaient deux : un qui apprenait à imiter les coups des joueurs et l’autre qui évaluait les positions.
- Enfin, la méthode de Monte-Carlo, qui permet de prévoir plusieurs coups à l’avance, a été abandonnée. Le nouvel algorithme d’apprentissage intègre directement l’évaluation des positions et des déplacements.
- Le réseau neuronal est mis à jour au fur et à mesure pour prédire les mouvements, ainsi que l’éventuel vainqueur des parties. Il est ensuite recombiné avec un algorithme de recherche pour créer une nouvelle version plus forte d’AlphaGo Zero, et le processus recommence pour aboutir à un programme toujours plus puissant et précis.
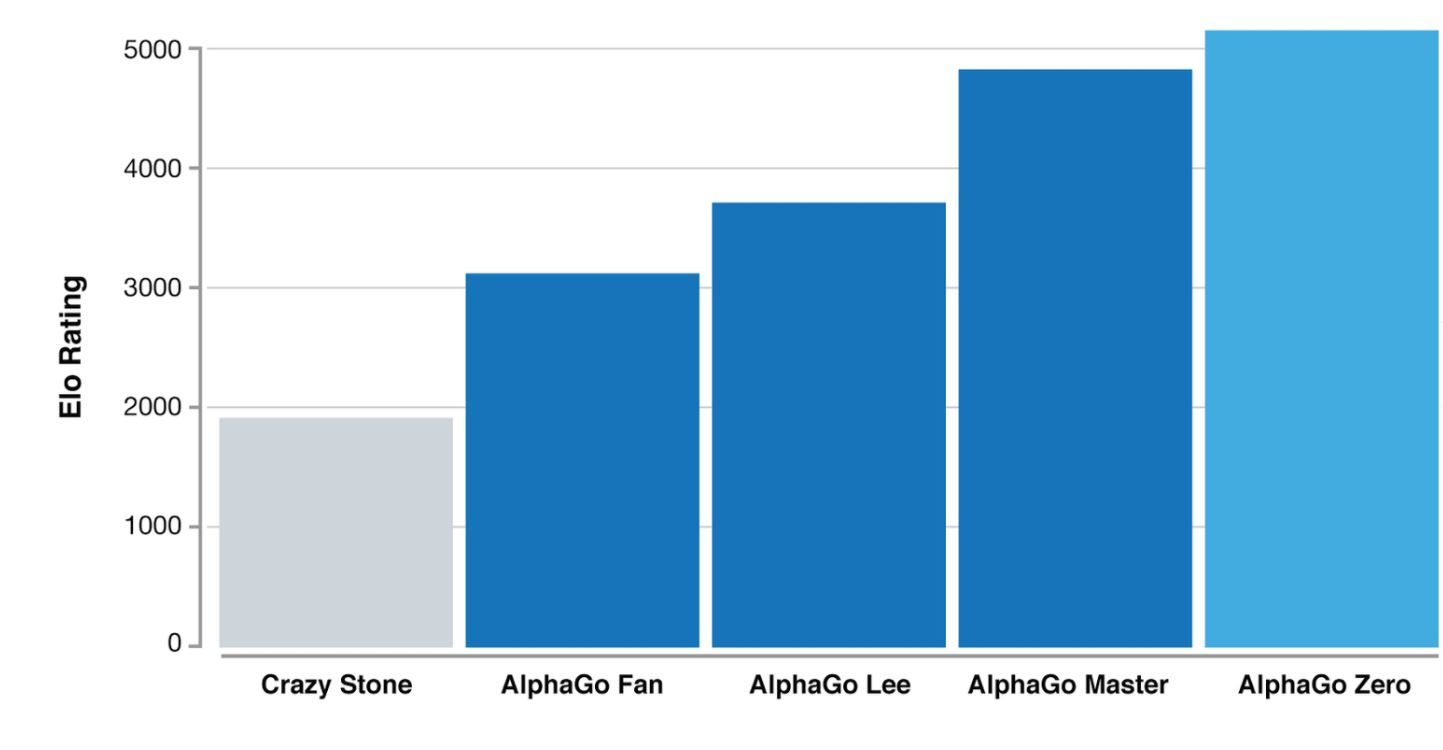
La machine progresse plus vite sans être contrainte par les connaissances humaines
DeepMind vient donc de prouver une nouvelle fois qu’il n’était pas nécessaire de collecter énormément de données pour faire du machine learning. L’absence de big data a même été un avantage dans ce cas présent car la machine a cessé d’imiter l’homme.
Au delà de la performance technique, AlphaGo Zero prouve également qu’en cessant d’imiter les techniques de jeu humaines, une intelligence artificielle gagne encore en efficacité. Affranchi de la connaissance des vrais joueurs dont elle avait appris tous les coups, AlphaGo Zero a fait preuve d’une grande créativité, développant des stratégies non conventionnelles et de nouveaux mouvements. « Cette technique est plus puissante que les versions précédentes d’AlphaGo car elle n’est plus contrainte par les limites de la connaissance humaine », résume le patron de DeepMind Demis Hassibis dans un post sur le site officiel.
Un véritable changement de paradigme. Le patron de DeepMind Demis Hassibis va jusqu’à reprendre, pour le compte de sa machine, le concept philosophique de « tabula rasa » qui reposait jusqu’à maintenant sur l’idée que l’esprit humain naîtrait vierge et se formerait uniquement par l’expérience.
Des applications dans l’énergie, les transports et la bio-informatique
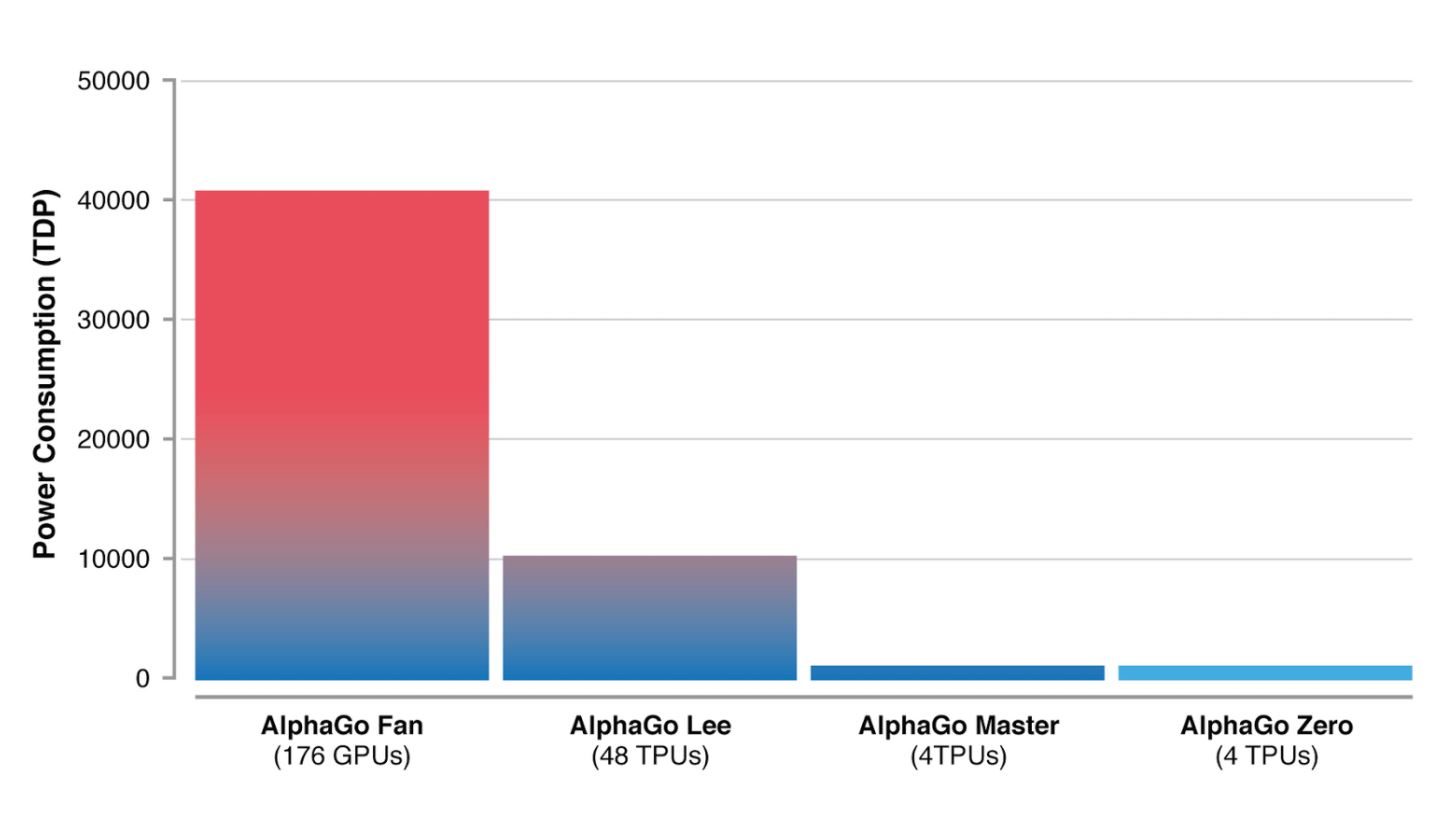
L’équipe de Deepmind a aussi rendu son intelligence artificielle beaucoup moins énergivore grâce à son nouvel algorithme. Tandis que la première version AlphaGo tournait avec 176 puces graphiques, la version Zero n’utilise plus que 4 TPU, des processeurs dédiés à l’apprentissage automatique conçus par Google. Une diminution impressionnante qui devrait rapidement trouver des applications. DeepMind planche déjà, en effet, sur la réduction de consommation d’énergie des data center de Google.
Nouveaux matériaux, recherche médicale et même résolution des mystères de l’univers, DeepMind ne voit pas de limite aux applications qui pourraient être rendues possibles grâce au travail effectué sur AlphaGo. La société collabore d’ailleurs déjà avec des cliniciens du National Health Service au Royaume-Uni.
Des ambitions tempérées par Tristan Cazenave : « la méthode de DeepMind ne peut s’appliquer à tout car il faut que le domaine soit bien défini. C’est le cas avec un jeu combinatoire comme le Go. On peut toutefois espérer optimiser la recherche dans les domaines de l’énergie, des transports ou encore de la bio-informatique grâce à leurs progrès », nous a-t-il confié.
Des soucis parfaitement résumés par le pape de la robotique Rodney Brooks Lors d’une keynote pour l’IEEE la semaine dernière, l’ingénieur a raconté avoir demandé aux créateurs d’AlphaGo si leur programme aurait pu s’adapter si on avait ajouté à la dernière minute une ligne sur le Goban, le plateau du jeu de Go, avant la rencontre contre Lee Sedol. Impossible, lui a répondu l’équipe : la machine aurait alors été incapable de gagner la moindre partie. AlphaGo Zero est peut-être imbattable au Go, mais loin d’avoir la souplesse de l’esprit humain.
🔴 Pour ne manquer aucune actualité de 01net, suivez-nous sur Google Actualités et WhatsApp.








