


Intel avait déjà dévoilé lundi 16 août dernier le nom commercial et la date de lancement de sa première génération de puces graphiques pour joueur. Et le géant des semi-conducteurs a remis le couvert ce jeudi 19 lors de sa conférence annuelle « Architecture Day » pour donner plus de détails quant à l’organisation interne de sa première génération de GPU « ARC » appelée « Alchemist ».
Connue jusqu’ici sous l’appellation « Xe-HPG », cette première entrée dans un marché dominé par Nvidia et AMD se doit de séduire. Séduire non seulement les potentiels clients, mais aussi les partenaires industriels (assembleurs de PC notamment) ou encore les développeurs. Une tâche énorme qui impose à Intel de remplir toutes les cases (matérielles, logicielles, technologiques, marketing, etc.) du premier coup, ou presque.
Au commencement était le Xe Core

Après des années de puces graphiques aux performances anémiques, Intel a dévoilé l’an dernier « Xe », une architecture graphique capable d’aller des simples GPU de PC portables basse consommation jusqu’au super GPU des supercalculateurs.
ARC Alchemist, prévu pour le premier trimestre 2022, fait partie de la famille « HPG », autrement dit « puce de jeu hautes performances ». Et en son sein opère le cœur « Xe », qui est sa brique fondamentale de conception des GPU. Exit les unités d’exécutions (EU) qui permettaient de comparer les puces mobiles précédentes (et l’Iris Max, avec ses 96 EU), il ne faut désormais raisonner qu’en cœur Xe et en « tranches » (lire plus bas).
Outre ses unités de chargement/déchargement, ses mémoires caches, etc. le cœur Xe est composé de 16 moteurs vectoriels (Vector Engines) et 16 moteurs matriciels (Matrix Engines). Les premiers traitent jusqu’à 256 bits par unité et par cycle, les seconds 1024 bits par unité et par cycle. Côté vectoriel, Anandtech, qui a fait le calcul, estime que le Xe core est ainsi équivalent aux Nvidia SM de l’architecture Ampère, ce qui n’est pas rien.
Là où le Xe se différencie des Nvidia SM, c’est du côté du calcul matriciel, avec deux fois plus d’unités. Intel miserait beaucoup sur ces calculs ainsi que sur les fonctions de calcul IA et autres réseaux neuronaux. Des technologies absentes des opérations de shaders dans les jeux actuels, mais qui pourraient prendre de l’ampleur dans le futur… Un futur très proche pour le suréchantillonnage sur lequel Intel compte beaucoup (lire plus loin).
Ray Tracing et Render Slices

Si les GPU sont utilisés autant pour le calcul intensif ou le minage de cryptomonnaies, c’est qu’ils sont champions de la parallélisation. Une force qui est le fait de leur organisation interne, agrégeant de nombreux cœurs. Dans le cas de Xe, Intel les a organisés en unités de quatre cœurs pour faire une Render Slice, littéralement « tranche de rendu ». Si le Xe core est bien l’unité fondamentale, l’unité fonctionnelle de base est en fait cette Render Slice et ses quatre cœurs.

L’américain va donc concevoir sa gamme de GPU « Alchemist » en empilant jusqu’à 8 de ces Render Slices, soit jusqu’à 32 cœurs Xe. Un progrès organisationnel puisque sa précédente architecture ne pouvait faire fonctionner de concert que 6 tranches. Il reste à voir si le niveau des performances (et donc de prix) ira jusqu’aux RTX3060, RTX3070, voire jusqu’à la RTX3080.
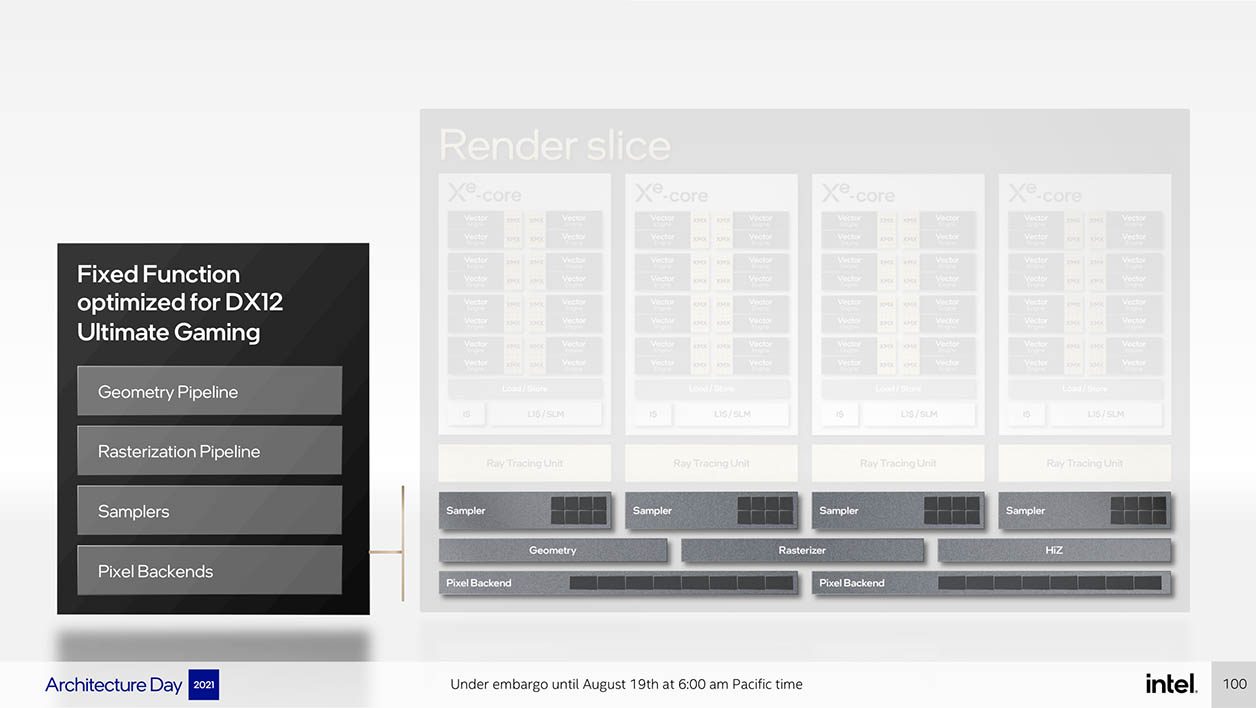
Un GPU, c’est plus que des cœurs collés entre eux : c’est aussi des « tuyaux » de mémoire pour faire circuler l’information (Memory Fabric) ainsi que des sous-unités de calcul et de routage de cette information. Outre les unités de rastérisation (qui transforment les triangles en images 2D pour nos écrans), chaque Xe core se voit affublé d’une unité dont vous avez sans doute entendu parler : une unité de Ray Tracing (RT).
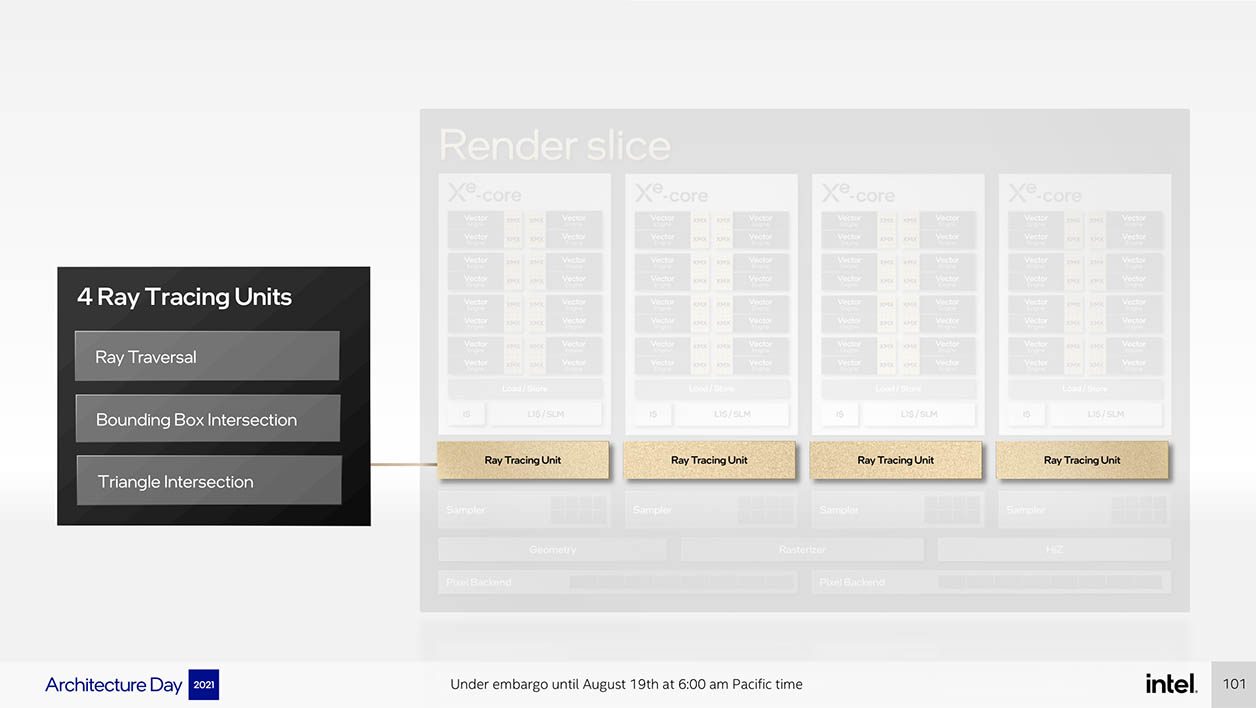
Dominé par Nvidia qui fut le précurseur de ces unités RT, le ray-tracing gagne doucement en popularité pour la qualité de ses effets de lumières et d’ombre. Impossible de se prononcer quant à la maturité des unités d’Intel par rapport à celle de Nvidia ou d’AMD, mais au moins on sait déjà que l’accélération est matérielle.
Fiche technique à la pointe, ersatz de DLSS
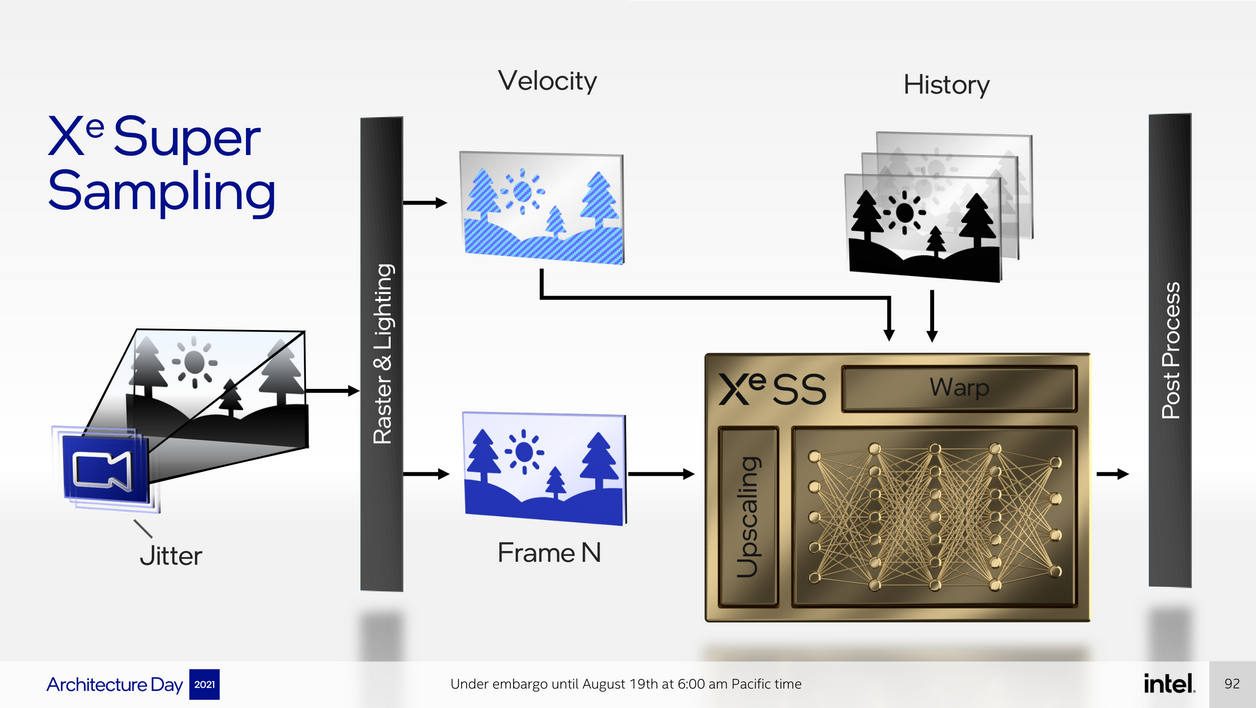
Le Ray-Tracing, comme on l’a vu, est de la partie. Mais l’architecture est aussi compatible avec toutes les fonctionnalités les plus avancées de DX12 Ultimate, tels que les Mesh Shaders (nouveau système de rendu d’image qui améliore les performances en limitant la complexité des objets lointains et simplifie le travail des développeurs) ou le Variable Rate Shading (VRS, qui économise des ressources en baissant la qualité sur des zones ou des moments de calculs). Et il y a même un genre de DLSS.

Appelé XeSS pour Xe Super Sampling, il s’agit d’une forme améliorée de suréchantillonnage (agrandissement d’une image, ndr). Comme pour le DLSS (Deep Learning Super Sampling) de Nvidia, le XeSS est une moulinette qui prend des images dans une définition initiale – par exemple du Full HD soit 1920 x 1080 points – et qui l’agrandit – par exemple en 4K – avec suffisamment d’astuce pour que l’image ne soit pas dégradée.
Comme chez Nvidia, Intel va tirer parti de certaines unités de calcul – les fameuses unités matricielles des cœurs Xe – pour obtenir un rendu de qualité et qui soit très rapidement calculé. De quoi permettre de jouer en 4K à fond les ballons sans avoir à sacrifier la fluidité d’image.
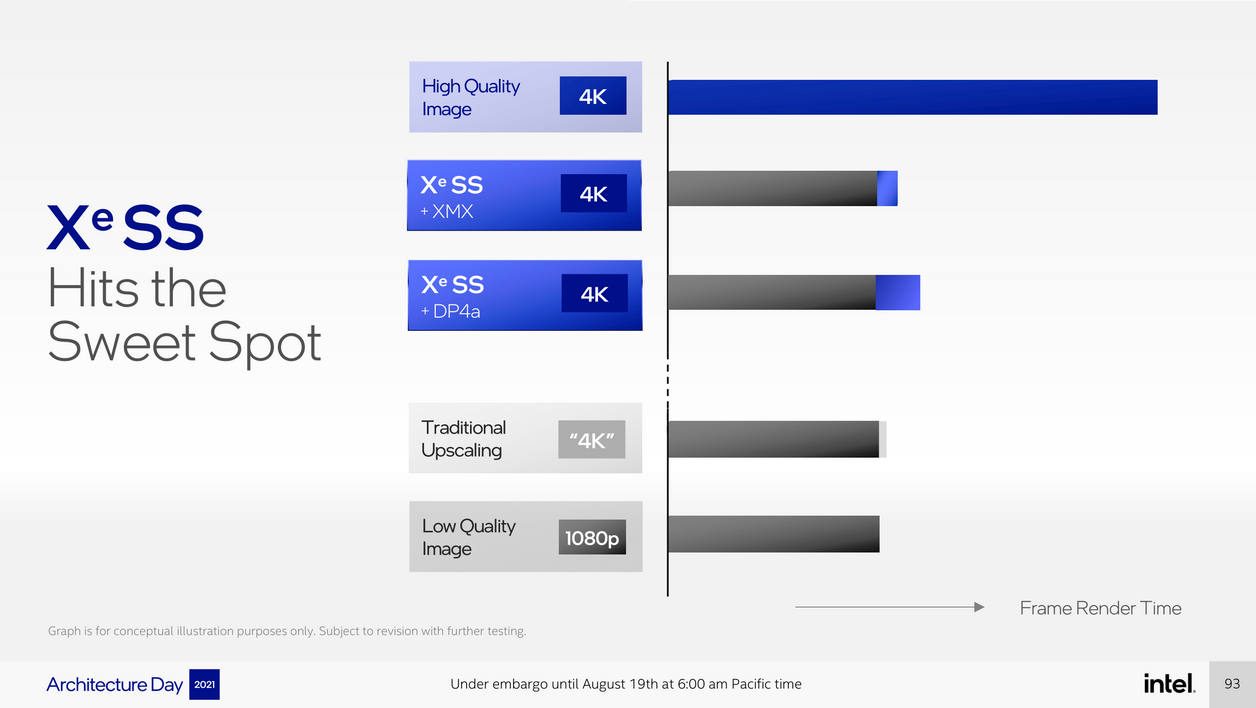
Mais contrairement à Nvidia, et comme son concurrent AMD, Intel développe aussi une version ouverte de son XeSS. Appelé Xe SS + DP4a, où cette dernière mention fait référence à des instructions présentes dans tous les GPU du monde ou presque, cette version est de moindre qualité et s’avère un peu moins performante, mais, comme le FidelityFX Super Resolution d’AMD, elle est universelle. En clair : la prochaine génération de puces graphiques d’Intel va ajouter une technologie sur la table pour améliorer les performances graphiques de toutes les puces existantes avec un minimum de concessions visuelles.
Une puce fabriquée par TSMC

Entre les HD Graphics traditionnelles et les puces Iris Plus de la 10e génération de Core, Intel avait doublé ses performances graphiques. L’arrivée de Iris Xe (nom de code Xe-LP) dans la 11e génération de Core avait encore doublé les performances, permettant un impressionnant x4 en seulement deux générations – ok, Intel partait de très loin !
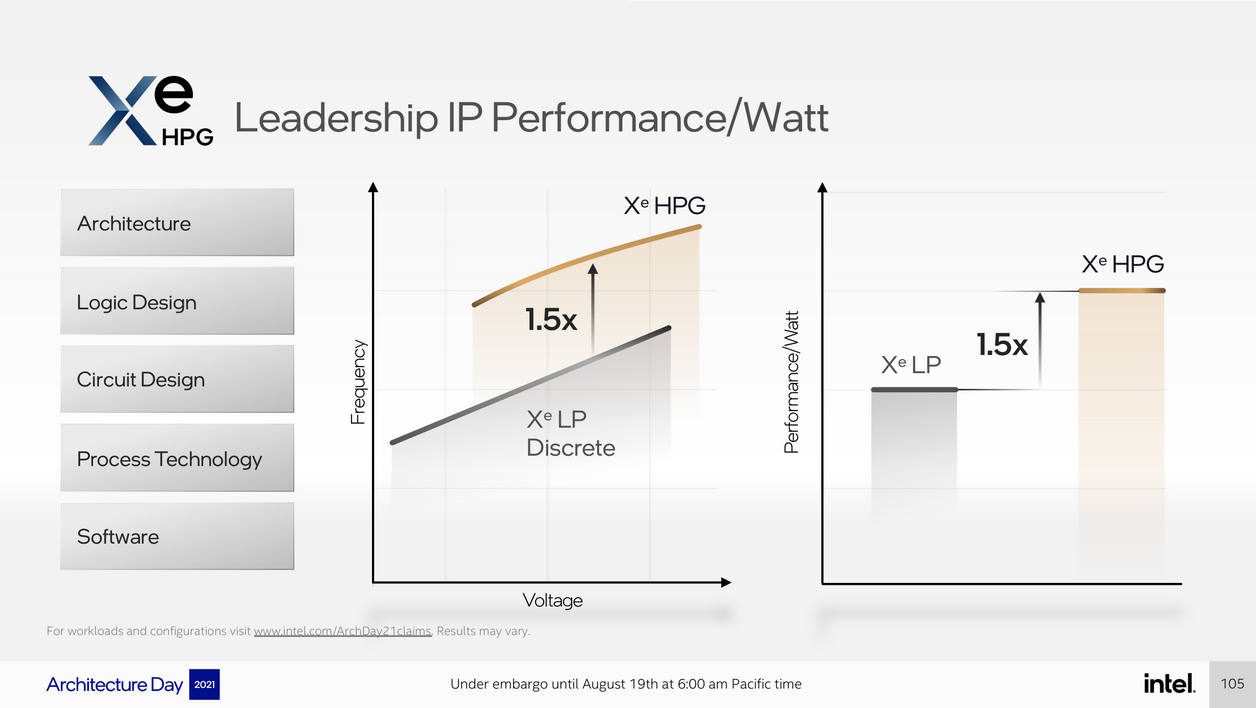
Si on ne connaît pas encore les performances finales des premières puces ARC Alchemist (Xe-HPG), Intel a confié que par rapport à Xe-LP, ses nouvelles puces sont capables de monter plus haut en voltage, plus haut en fréquences et offrent 50% de performances par watt en plus. Si on ajoute à cela la nouvelle architecture et bien plus de cœurs sur les puces les plus haut de gamme, on est en droit d’en attendre beaucoup.

Détail cocasse : une des clés de cette capacité de monter en fréquence est le procédé de fabrication qui sera sous la coupe… du Taïwanais TSMC. Celui qui produit déjà certaines des puces de Nvidia (hors RTX3000, produites par Samsung) et toutes les puces d’AMD sera aux commandes de la production des Intel ARC. Les puces seront gravées en 6 nm selon le procédé N6 de TSMC, une évolution de son procédé 7 nm FinFET qui offre de très bons rendements tout en s’appuyant en partie sur de la gravure EUV.
Comprendre qu’il s’agit là d’un procédé tout à la fois récent (l’industrialisation de masse a débuté fin 2020), et fiable, avec des coûts en partie réduits par l’usage de l’EUV (qui réduit le nombre de masques donc le nombre d’étapes).

Sans pouvoir pour l’heure juger des performances, même si on sait qu’elles ne pourront égaler Nvidia ou AMD dans le haut de gamme, les premiers détails de la structure des futures puces ARC Alchemist nous renseignent beaucoup. Ils montrent qu’Intel a une stratégie long terme (quatre générations annoncées), que les puces sont conçues autant pour les jeux d’aujourd’hui (RT, VRS) que pour les jeux du futur (Mesh Shaders, unités matricielles). Mais aussi que l’approche d’Intel est la fois globale – implication logicielle Appelé Xe SS + DP4a, etc. – et pragmatique, avec le choix d’un partenaire (TSMC) qui grave mieux que lui.
À découvrir aussi en vidéo :
Intel ne s’est donc pas lancé dans le combat la fleur au fusil et a bien mis toutes les chances de son côté pour affronter les géants des GPU. Cela suffira-t-il ? Premiers éléments de réponse début 2022 avec l’arrivée des premiers tests comparatifs, de l’évaluation des compatibilités logicielles ainsi que les sacro-saintes mesures de performances/prix. Le nerf de la guerre pour les joueurs.
🔴 Pour ne manquer aucune actualité de 01net, suivez-nous sur Google Actualités et WhatsApp.












